권철민 저, '파이썬 머신러닝 완벽 가이드', 2019.02.28
내 맘대로 요약 공부 중(문제시 비공개 및 삭제)
최초 작성일 2020.12.13
7.1 LightGBM
- 기존 GBM과 XGBoost의 후속작. 동일 성능 대비 학습 시간이 매우 짧음
- 적은 데이터에 과적 합할 가능성이 있음(10,000건 이하 거의 안된다고 보는 게 맞을 듯?)
- 리프 중심 트리 분할(Leaf Wise) 방식(보통은 균형 트리 분할(Level Wise) 방식을 사용하고 있음)
- 사이킷런 LightGBM(분류 LGBMClassifer, 회귀 LGBMRegressor)
- 사용하기 위해 Visual Studio Build tool 2015 이상 필요
- visualstudio.microsoft.com/ko/downloads/
Windows 및 Mac용 Visual Studio 2019 다운로드
Visual Studio Community, Professional, Enterprise를 다운로드하세요. 지금 Visual Studio IDE, Code 또는 Mac을 무료로 사용해 보세요.
visualstudio.microsoft.com
Command창 관리자 권한으로 실행, conda install -c conda-forge lightgbm
- 주요 파라미터
| 파라미터 | 설명 |
| num_iterations [n_estimators] |
반복 수행하는 트리의 개수 지정, 너무 많으면 과적화, Default=100 |
| learning_rate | 부스팅 스텝 중 업데이트되는 학습률, 0 ~ 1 사이값, Default=0.1 |
| max_depth | 트리 기반 알고리즘 동일, Default=-1(제한없음) |
| min_data_in_leaf | 리프 노드가 되기 위해 필요한 최소 데이터 수, Default=20 |
| num_leaves | 하나의 트리가 가질 수 있는 최대 리프 개수, Default=31 |
| boosting | 부스팅의 트리를 생성하는 알고리즘 선택, gbdt(일반 그래디언트) OR rf(랜덤 포레스트), Default=gbdt |
| bagging_fraction | 트리가 커져서 과적합 되는 것을 방지하기 위해 데이터 샘플링 비율 지정, Default=1 |
| feature_freation | 개별 트리 학습 시 무작위로 선택하는 피처의 비율, 과적합 방지, Default=1 |
| lambda_l2 | L2 Regulation, 피처가 많을 경우 검토, 값이 클수록 과적합 감소하는 경향 |
| lambda_l1 | L1 Regulation, 피처가 많을수록 검토, 값이 클수록 과적합 감소하는 경향 |
- Learning Task 파라미터
| Learning Task 파라미터 | 설명 |
| objective | 최솟값을 가져야 할 손실함수 정의, XGBoost의 objective 파라미터와 동일 |
- 주요 파라미터 튜닝 방안
- num_leaves 개수를 중심으로 min_data_in_leaf, max_depth를 조정
- num_leaves의 개수를 높이면 정확도가 증가하지만 과적합 발생 가능성이 높음
- min_data_in_leaf의 개수를 높이면 과적합 발생 가능성은 낮아지고, 정확도 또한 감소
- max_depth의 개수를 높이면 정확도가 증가하지만 과적합 발생 가능성이 높음
- learning_rate를 줄이면서 n_estimators를 크게 하는 방법도 있음
- 데이터의 퀄리티에 따라 파라미터 튜닝은 유연하게 대처해야 함
- 파이썬 LightGBM, 사이킷런 LightGBM, 사이킷런 XGBoost 파라미터 비교
| 유형 | 파이썬 LightGBM | 사이킷런 LightGBM | 사이킷런 XGBoost |
| 파라미터명 | num_iterations | n_estimators | n_estimators |
| learning_rate | learning_rate | learning_rate | |
| max_depth | max_depth | max_depth | |
| min_data_in_leaf | min_child_samples | N/A | |
| baggig_fraction | subsample | subsample | |
| feature_fraction | colsample_bytree | colsample_bytree | |
| lambda_l2 | reg_lambda | reg_lambda | |
| lambda_l1 | reg_alpha | reg_alpha | |
| early_stopping_round | early_stopping_rounds | early_stopping_rounds | |
| num_leaves | num_leaves | N/A | |
| min_sum_hessian_in_leaf | min_child_weight | min_child_weight |
- 파이썬 LightGBM의 lightgbm에서 LGBMClassifier 사용, 위스콘신 유방암 데이터 세트 활용
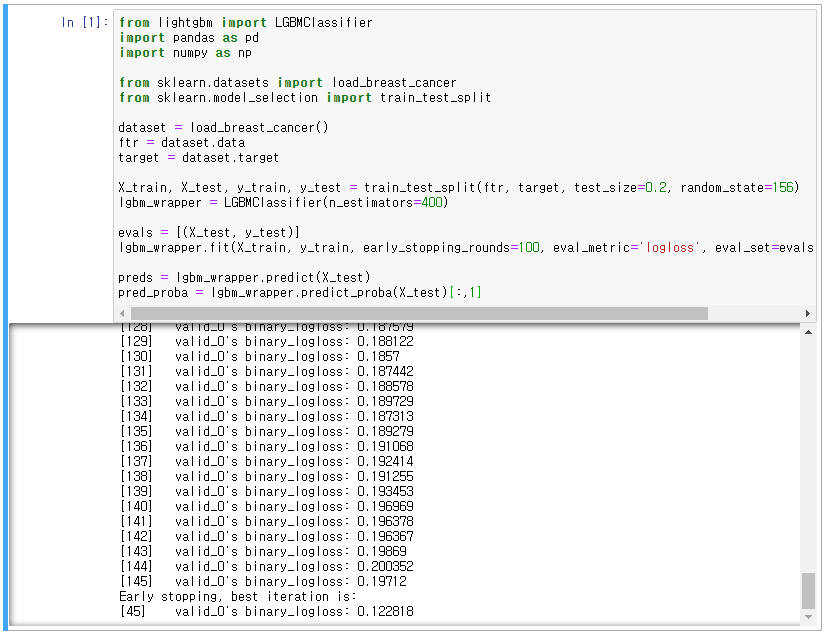

- XGBoost와 동일하게 plot_importance() API로 시각화
- 실습 예제는 추후 진행 예정
7.2 분류 실습(캐글 산탄데르 고객 만족 예측)
- 370개의 피처가 주어진 데이터 세트에서 고객 만족 여부를 예측
- 클래스 레이블 명: TARGET, =1 불만을 가진 고객, =0 만족한 고객
- kaggle.com/c/santander-customer-satisfaction/data
Santander Customer Satisfaction
Which customers are happy customers?
www.kaggle.com
- Kaggle 경연 규칙에 동의 후 Download All
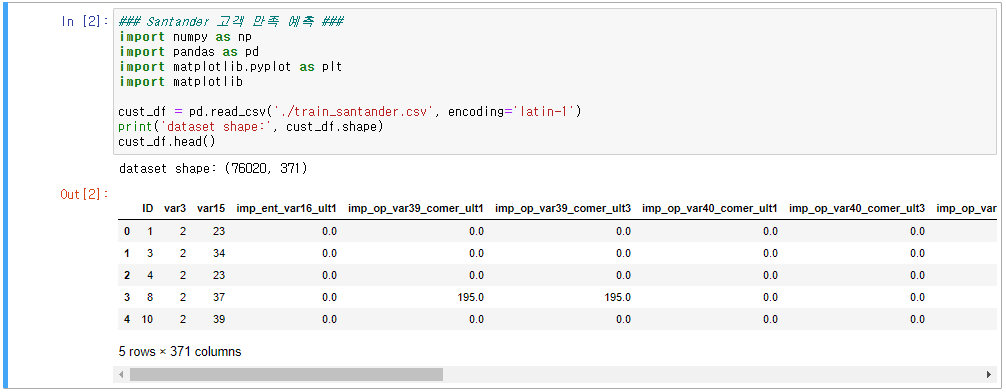
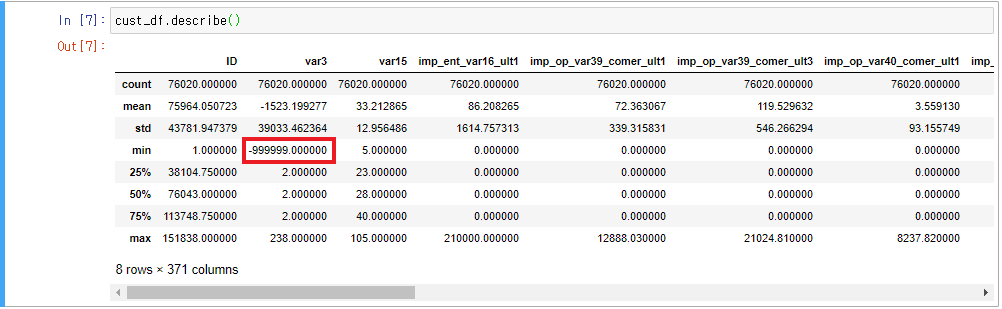
- 데이터 확인



- XGBoost 모델 학습, ROC AUC 평가
- n_estimators = 500, early_stopping_rounds=100, eval_metric = 'auc'
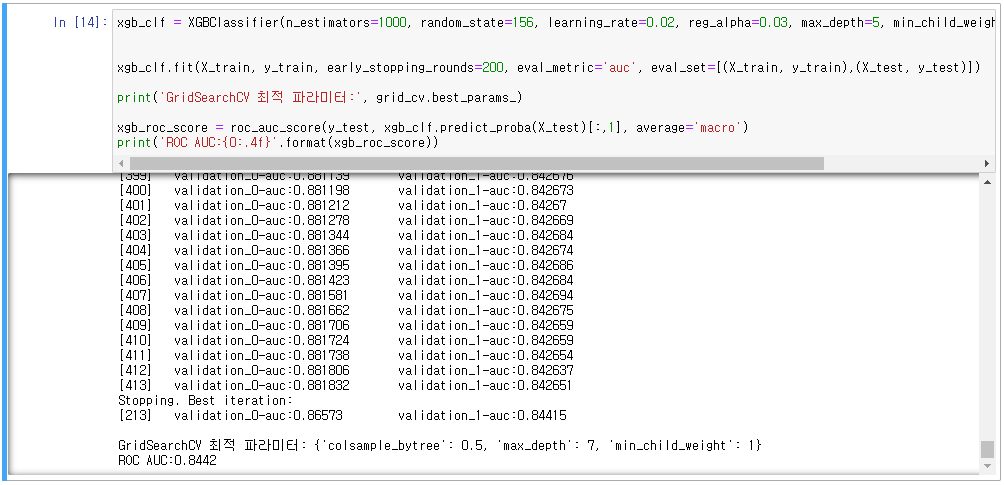
- XGBoost 파라미터 튜닝(n_estimators, early_stopping_rounds, max_depth, min_chind_weight, colsample_bytree)
- 교차검증 추가(GridSearchCV)

- colsample_bytree:0.75, max_depth:5, min_child_weight:1, n_estimators=1000, learning_rate=0.02, reg_alpha=0.03,
early_stopping_rounds=200
- 시각화(xgboost 모듈의 plot_importance() 활용)
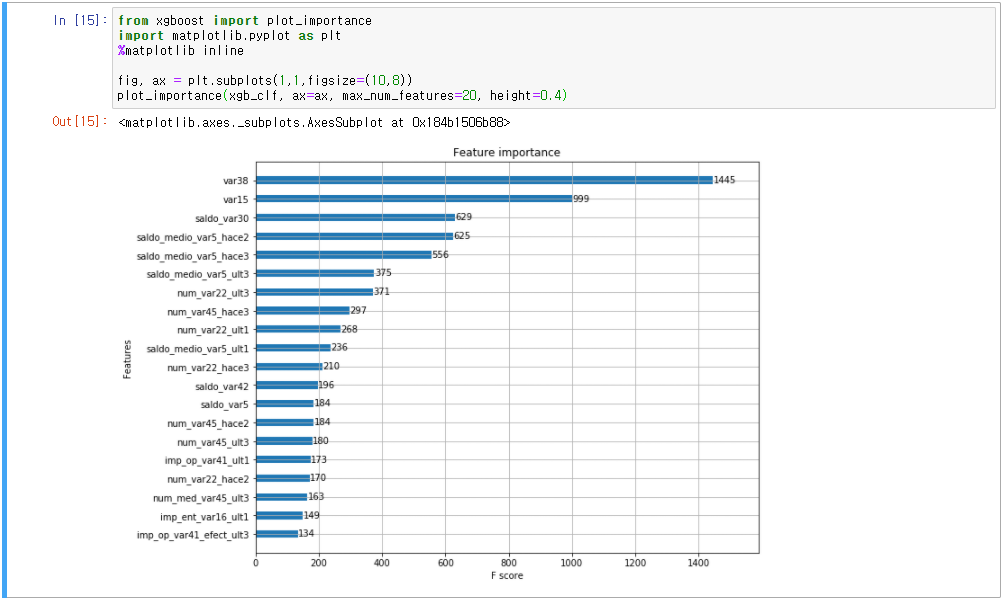
- LightGBM 모델 학습, ROC-AUC 평가
- n_estimators = 500, early_stopping_rounds=100, eval_metric = 'auc'

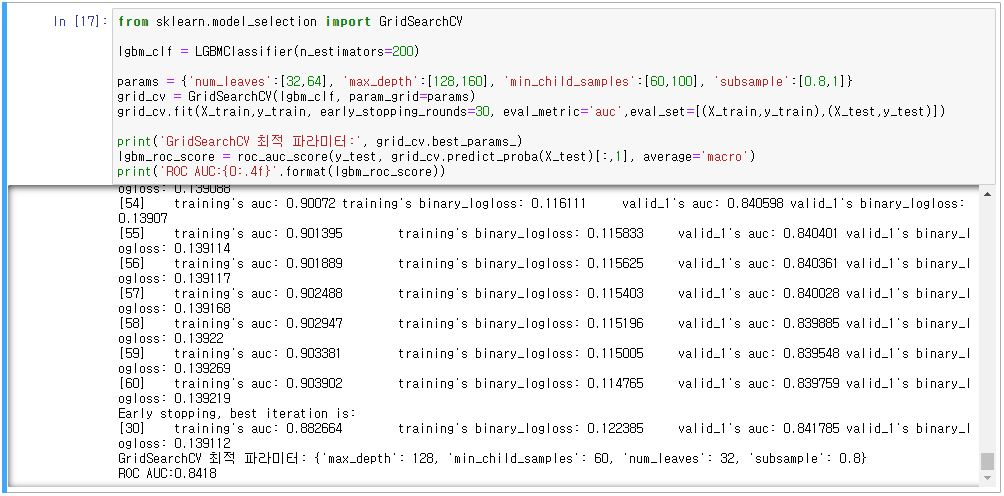
- LightGBM 파라미터 튜닝(num_leaves, max_depth, min_child_samples, subsample)
- 교차검증 추가
7.3 분류 실습(캐글 신용카드 사기 검출)
- www.kaggle.com/mlg-ulb/creditcardfraud
Credit Card Fraud Detection
Anonymized credit card transactions labeled as fraudulent or genuine
www.kaggle.com
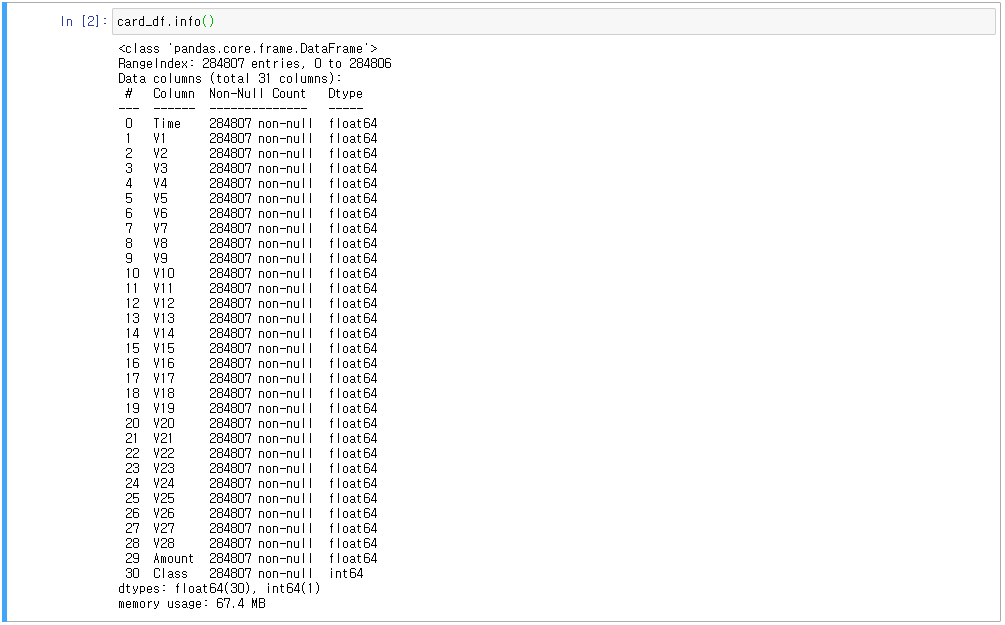
- 데이터 확인

- 오버 샘플링과 언더 샘플링(데이터 분포량 불균형 해결)
1. 오버 샘플링
- 적은 데이터를 증식하여 학습을 위한 충분한 데이터를 확보하는 방법
- SMOTE(Synthetic Minority Over-Sampling Technique): 적은 데이터에 있는 개별 데이터들의 K 최근접 이웃(K Nearest Neighbor)를 찾아 원 데이터와 K개 이웃의 차이를 일정값으로 만들어 원 데이터와 약간 차이가 있는 새로운 데이터를 생성
2. 언더 샘플링
- 많은 데이터를 적은 데이터로 감소시키는 방법
- 정상적인 데이터를 너무 많이 감소시키기 때문에 오히려 제대로된 학습을 수행할 수 없음(잘 안쓰임)
- SMOTE 파이썬 패키지 imbalanced-learn 활용
conda install -c conda-forge imbalanced-learn
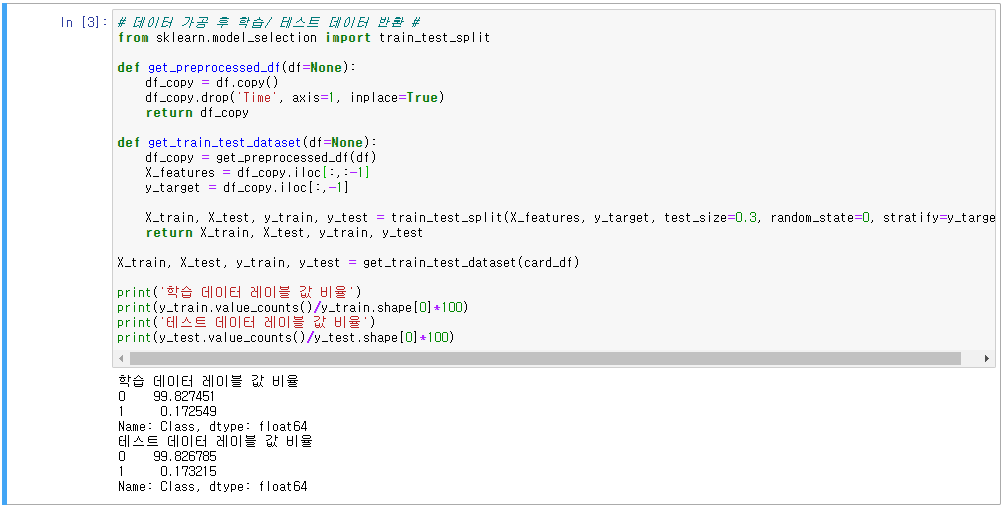
1. 원본 데이터 성능
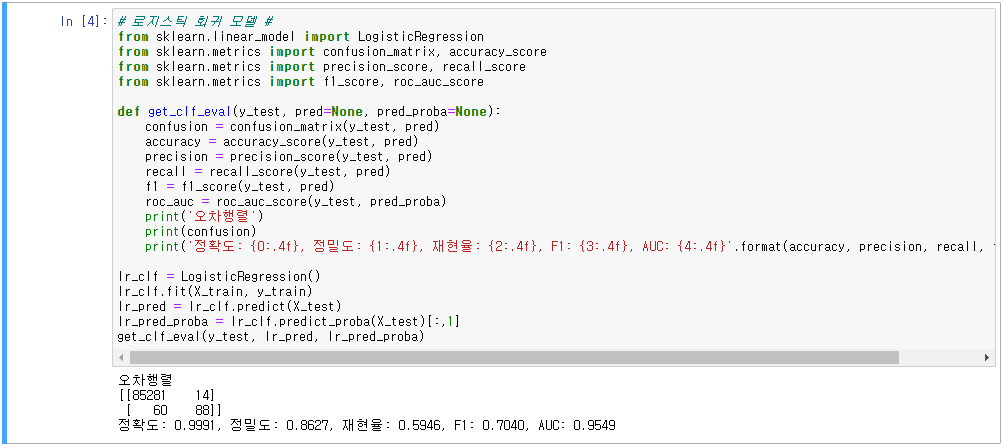

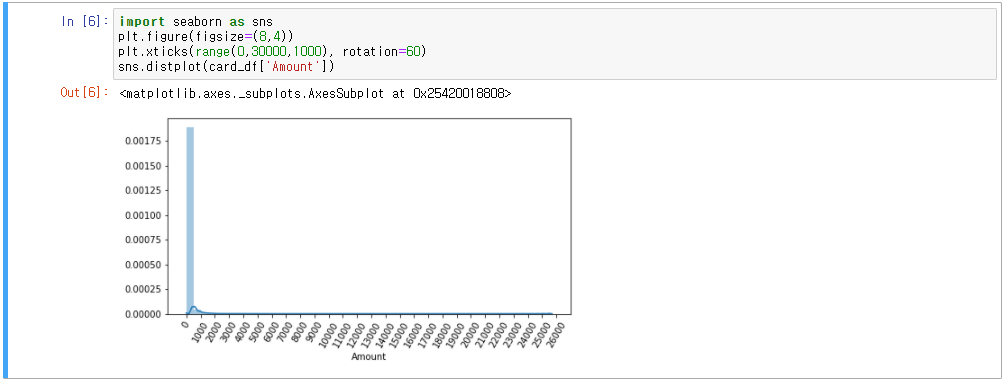
2. 데이터 분포도 변환 후 성능
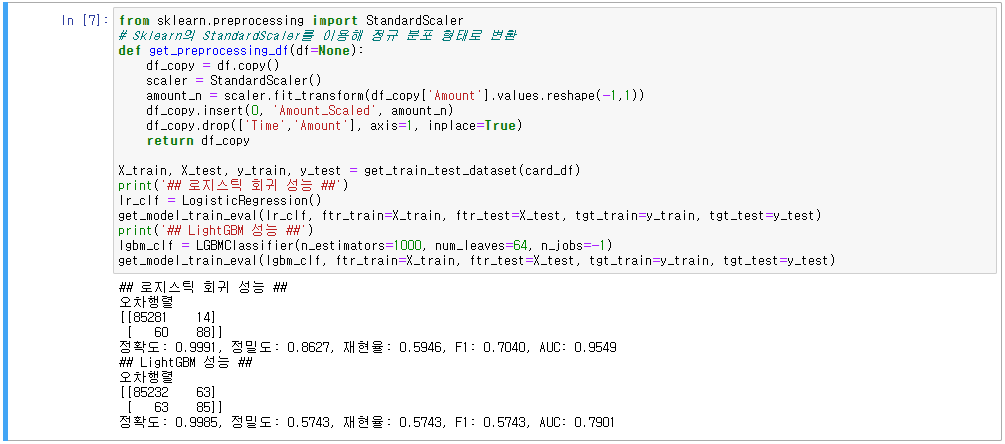

3. 이상치 데이터 제거 후 성능
- 이상치 데이터(Outlier) 선정 방법, IQR(Inter Quantile Range) 방식
- IQR은 사분위(Quantile)값의 편차를 이용하는 기법

- 어떤 피처의 이상치 데이터를 검출할 것인지 선택부터!
- 레이블과 가장 상관성이 높은 피처를 위주로 이상치를 검출하는 것이 유리
- Dataframe의 corr()을 활용하여 피처별 상관도를 구하여 시각화
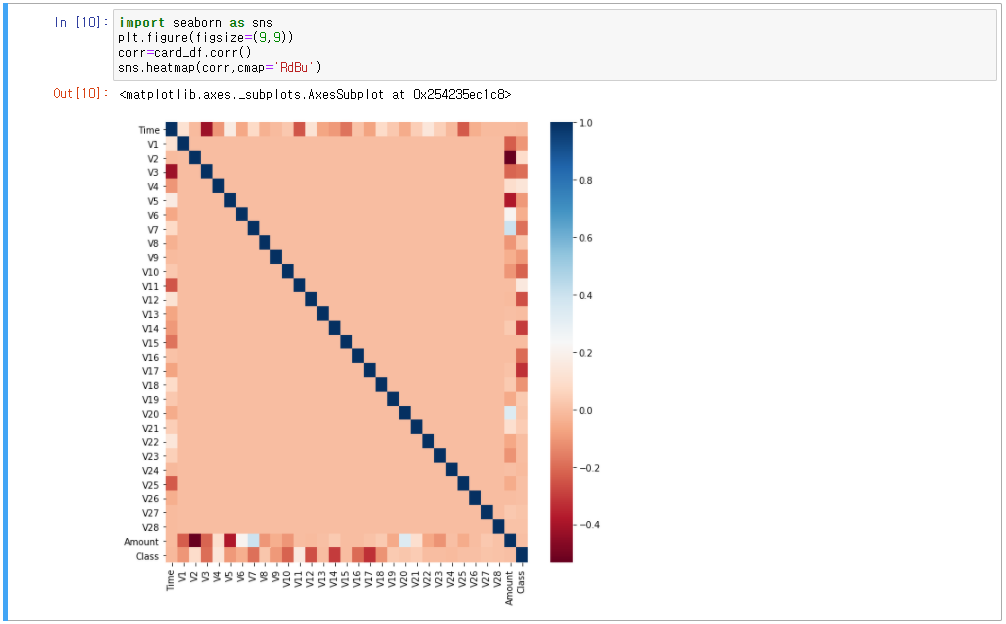
- IQR을 이용해 이상치를 검출하는 함수 생성(get_outlier()함수는 인자로 DataFrame과 이상치를 검출한 칼럼을 받음)
- Numpy의 percentile()을 이용해 1/4분위수, 3/4분위수를 구함


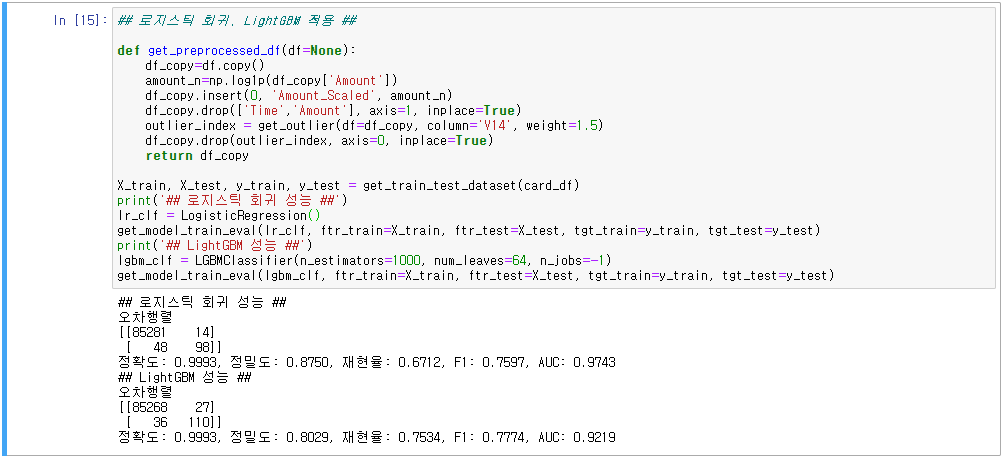
4. SMOTE 오버 샘플링 적용 후 성능
- imbalanced_learn 패키지 활용


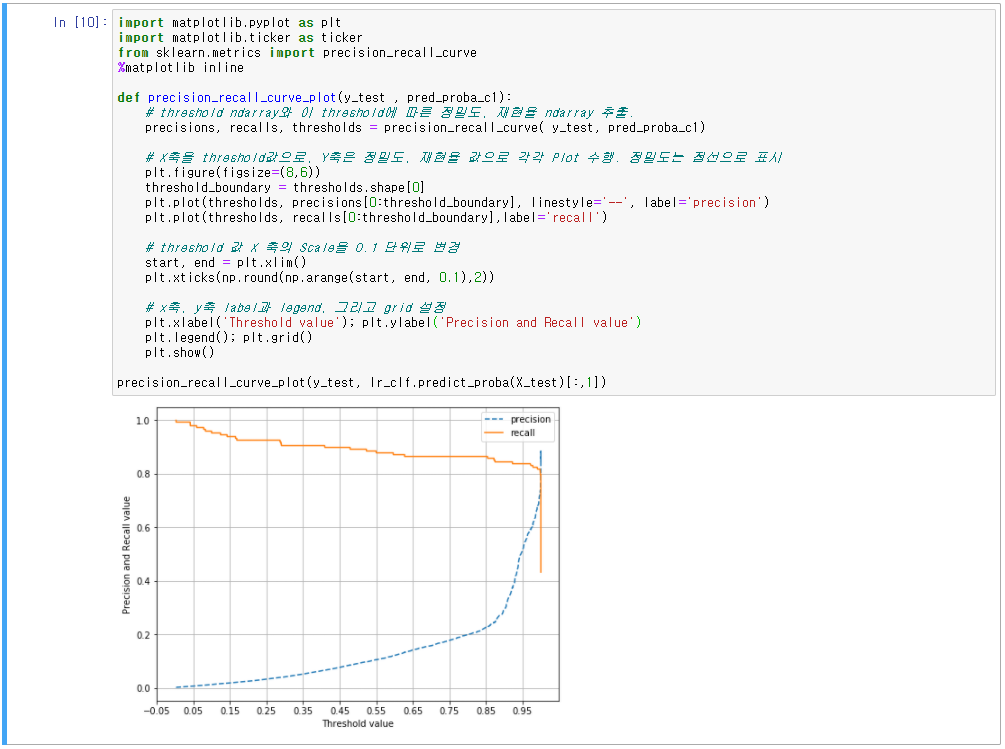

- 가장 좋은 성능을 보여주는 것은 SMOTE 오버 샘플링 LightGBM
7.4 스태킹 앙상블(Stacking Ensemble)
- 여러 개의 모델에 대한 예측값을 합한 후(스태킹 형태로 쌓은 뒤), 이에 대한 예측을 다시 수행
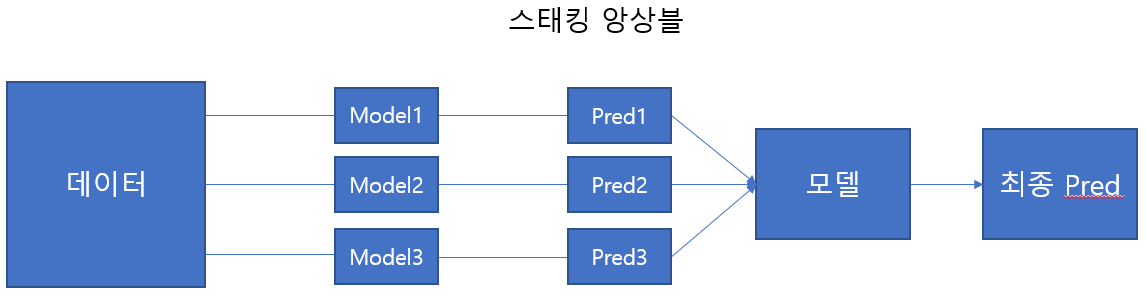
- 위스콘신 유방암 데이터 활용
- 초기 모델: KNN, 랜덤 포레스트, 결정트리, 에이다 부스트 / 최종모델: 로지스틱 회귀





- 스태킹 기법을 사용한다고 무조건 성능이 좋아지지는 않음
- CV 세트 기반의 스태킹(교차검증 학습 데이터, 교차검증 테스트 데이터로 최종 모델 학습 및 평가)
Step1. 각 모델별로 학습/테스트 데이터를 예측한 결과 값을 기반으로 최종 모델용 학습/테스트 데이터 생성
- 최종 모델에서 사용될 학습/테스트용 데이터를 교차 검증을 통해서 생성
Step2. 교차검증으로 생성된 학습/테스트용 데이터를 스태킹 형태로 합친 뒤, 스태킹된 학습데이터로 학습하고 스탱킹된 테스트 데이터를 예측하여, 원본 테스트 데이터의 레이블을 기반으로 평가




'코딩 > Machine Learning' 카테고리의 다른 글
| 9. 회귀(Regression)_2 (0) | 2021.01.01 |
|---|---|
| 8. 회귀(Regression)_1 (0) | 2020.12.27 |
| 6. 분류(Classification)_2 (1) | 2020.12.13 |
| 5. 분류(Classification)_1 (0) | 2020.12.10 |
| 4. 평가(분류 평가) (1) | 2020.11.29 |




댓글