권철민 저, '파이썬 머신러닝 완벽 가이드', 2019.02.28
내 맘대로 요약 공부 중(문제시 비공개 및 삭제)
최초 작성일 2020.12.10
5.1 분류(Classification)의 개요
- 지도학습은 레이블(Label)이라는 명시적인 정답이 있는 데이터로 학습하는 머신러닝 방식
- 지도학습의 대표적인 유형, 분류(Classification)
- 분류는 학습 데이터의 피처(특징)와 레이블(정답)을 머신러닝 알고리즘으로 학습하여 모델을 생성하고, 미지의 값이 주어졌을 때 미지의 레이블 값을 예측하는 것
- 대표적인 분류 알고리즘
1. 베이즈(Bayes) 통계와 생성 모델에 기반한 나이브 베이즈(Naive Bayes)
2. 독립변수와 종속변수의 선형 관계성에 기반한 로지스틱 회귀(Logistic Regression)
3. 데이터 균일도에 따른 규칙 기반의 결정 트리(Decision Tree)
4. 개별 클래스 간의 최대 분류 마진을 효과적으로 찾아주는 서포트 벡터 머신(Support Vector Machine)
5. 근접 거리를 기준으로 하는 최소 근접 알고리즘(Nearest Neighbor)
6. 심층 연결 기반의 신경망(Neural Network)
7. 서로 다른 머신러닝 알고리즘을 결합한 앙상블(Ensemble)
5.2 결정 트리(Decision Tree)
- 데이터에 있는 규칙을 학습하여 트리(Tree) 기반의 분류 규칙 모델을 만드는 것
- 데이터의 어떤 기준을 바탕으로 규칙을 만드는지에 따라 성능이 크게 달라짐
- 규칙 노드는 규칙 조건, 리프 노드는 결정된 클래스 값
- 새로운 규칙 조건(새로운 규칙 조합) 마다 서브 트리(Sub Tree)가 생성
- 규칙이 많으면 많을수록 분류하기 어렵다는 의미이며 트리가 더욱 복잡해지는데, 트리의 깊이(Depth)가 깊을수록 예측 성능이 저하될 우려가 있음
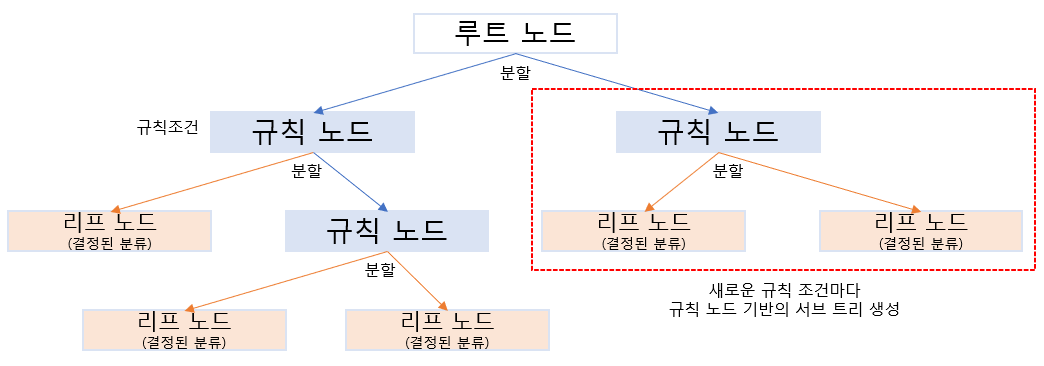
- 가능한 적은 노드로 많은 데이터가 분류될 수 있는 규칙을 찾는 것이 결정 트리의 핵심
- 어떠한 규칙 조건이 많은 데이터를 분류할 수 있는가? → 정보의 균일도 측정(정보이득, 지니계수)
1. 정보이득이란?
엔트로피 개념은 주어진 데이터의 혼잡도를 의미하는데, 서로 다른 값이 섞여 있으면 엔트로피가 높고 같은
값이 섞여 있으면 엔트로피가 낮은 게 특징. 정보이득이 높은 규칙을 기준으로 분할함
정보이득 = 1- 엔트로피
2. 지니계수란?
불평등 지수를 나타내는 경제학 계수. 0이 가장 평등하며 1로 갈수록 불평등함. 머신러닝에서는 데이터가 다양한 값을 가질수록 평등하며 특정 값으로 쏠릴 경우 불평등함. 즉, 다양성이 낮을수록 균일도가 높다는 의미로 1에 가까울수록 데이터 균일도가 높음. 지니계수가 높은 규칙을 기준으로 분할함

- 결정 트리 모델의 장·단점
1. 장점: 쉽고 직관적이며, 피처의 스케일링이나 정규화 등의 전처리 작업의 영향이 적음
2. 단점: 과적합(Overfitting)으로 알고리즘 성능이 저하되기 쉽다
3. 단점을 극복하기 위한 대책: 트리의 크기를 사전에 제한하여 과적합을 방지
- 결정 트리 파라미터: sklearn의 DecisionTreeClassifier API 활용(지니 계수를 이용하여 데이터를 분할함)
| 파라미터 명 | 설명 |
| min_samples_split | 노드를 분할하기 위한 최소한의 샘플 데이터 수(과적합 방지) Default = 2, 작게 설정할수록 분할되는 노드가 많아지며 과적합 가능성 증가 |
| min_samples_leaf | 리프 노드가 되기 위한 최소한의 샘플 데이터 수(과적합 방지) 비대칭 데이터의 경우 특정 클래스의 데이터 수가 극히 적을 수 있으므로 작게 설정 |
| max_features | 최적의 분할을 위해 고려할 최대 피처 수 Default = None, 모든 피처를 사용해 분할 수행 int형 → 피처의 개수, float형 → 전체 피처 중 대상 피처의 퍼센트 개수 'sqrt' → √(전체 피처수), 'auto' → 'sqrt' 동일 'log' → log2(전체 피처수) |
| max_depth | 트리의 최대 깊이 설정(과적합 방지) Default = None, 완벽하게 분류될 때까지 분할 깊이가 깊어지면 min_samples_split 만큼 최대 분할 할 수 있으므로 적정값으로 설정 |
| max_leaf_nodes | 말단 노드의 최대 개수 |
- 결정 트리 모델의 시각화
- Graphviz 패키지, sklearn의 export_graphviz() API 활용
- 학습이 완료된 Estimator, 피처의 이름 리스트, 레이블 이름 리스트 입력 → 시각화
- Graphviz 윈도우 설치
1. https://graphviz.gitlab.io/_pages/Download/Download_windows.html
Redirecting…
graphviz.gitlab.io


2. 아나콘다(Anaconda) 콘솔에서 pip install graphviz 실행

3. 환경변수 추가



☆환경변수 오류 발생 시 대처사항
Error: failed to execute ['dot', '-Tsvg'], make sure the Graphviz executables are on your systems' PATH


4. 트리 모델 생성 확인



- petal length(cm) → 자식 노드를 만들기 위한 규칙 조건, 이 조건이 없으면 리프 노드
- gini → value=[]로 주어진 데이터 분포에서의 지니 계수
- samples → 현 규칙에 해당하는 데이터 수
- value=[] → 클래스 값 기반의 데이터 건수, value=[10,11,12]는 Class1 10개, Class2 11개, Class3 12개를 의미
- 각 노드의 색 → 붓꽃 데이터의 레이블 값, 주황색: 0, 초록색: 1, 보라색: 2, 색이 짙을수록 지니계수가 낮음
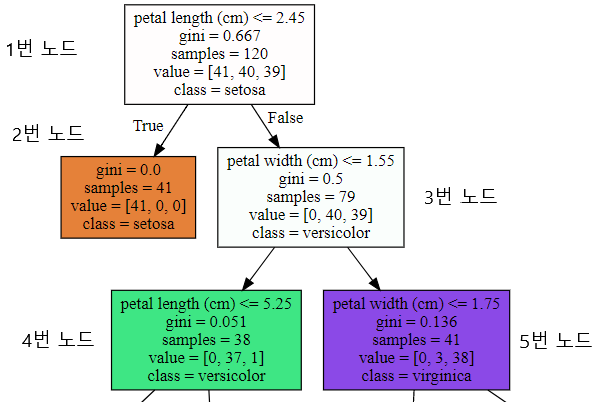
- 1번 노드
- samples = 120, 전체 데이터 수 120개
- value = [41, 40, 39], Setosa 41개, Versicolor 40개, Virginica 39개로 데이터 구성
- sample 120개가 [41, 40, 39] 분포도로 되어 있음, 지니계수 0.667
- petal length(cm) <=2.45 규칙으로 자식 노드 생성
- class = setosa, 하위 노드를 가질 경우에 setosa의 개수가 41개로 가장 많다는 의미
- 2번 노드
- petal length(cm) <=2.45 True
- samples = 41개가 모두 setosa 이므로 지니계수 0
- 3번 노드
- sample 79개 중 Versicolor 40개, Virginica 39개로 지니계수 0.5
- petal width(cm) <=1.55 규칙으로 자식 노드 생성
- 4번 노드
- petal width(cm) <= 1.55 True
- sample 38개 중 Versicolor 37개, Virginica 1개, 지니계수 0.051
- petal length(cm) <=5.25 규칙으로 자식 노드 생성
- 5번 노드
- sample 41개 중 Versicolor 3개, Virginica 38개, 지니계수 0.136
- petal width(cm) <=1.75 규칙으로 자식 노드 생성



- sklearn은 결정 트리에서 피처의 역할 지표를 DecisionTreeClassifier 객체의 feature_importances_ 로 제공

- 결정 트리 과적합(Overfitting)
1. sklearn의 분류를 위한 테스트용 데이터 만들 수 있는 make_classification() API 활용
2. 2개의 피처가 3가지 유형의 클래스 값을 갖는 임의의 데이터 세트 생성 및 시각화

3. visualize_boundary() 함수, 결정 경계를 표시하여 모델의 분류 성능을 시각화


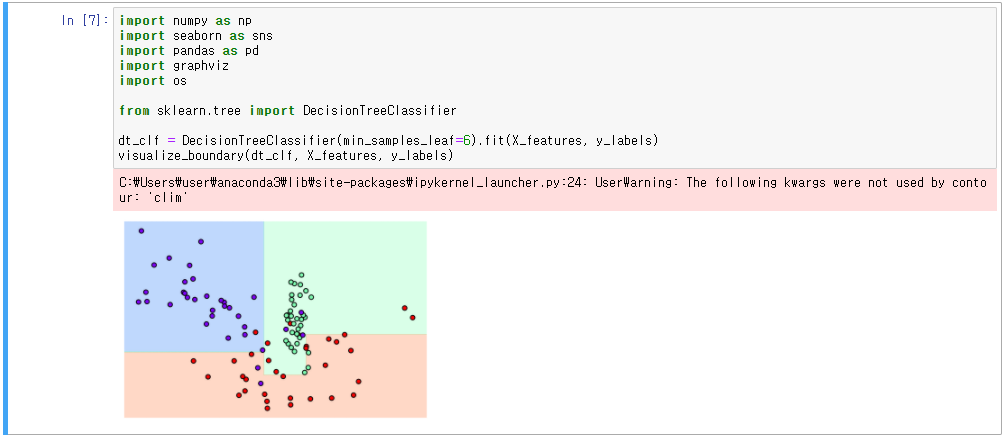
4. 파라미터 = Default, 엄격한 분할 기준으로 결정 기준 경계가 복잡해짐
5. min_samples_leaf = 6, 좀 더 일반화되어 분류된 것을 알 수 있음
- 결정 트리 실습(사용자 행동 인식 데이터 세트, Human Activity Recognition)
1. 사람의 동작과 관련된 여러 가지 피처를 수집한 데이터, 수집된 피처를 바탕으로 어떤 동작인지 예측해보자
2. http://archive.ics.uci.edu/ml/datasets/Human+Activity+Recognition+Using+Smartphones
UCI Machine Learning Repository: Human Activity Recognition Using Smartphones Data Set
Human Activity Recognition Using Smartphones Data Set Download: Data Folder, Data Set Description Abstract: Human Activity Recognition database built from the recordings of 30 subjects performing activities of daily living (ADL) while carrying a waist-moun
archive.ics.uci.edu






3. GridSearchCV를 사용하여 map_depth 값을 조절하며 예측 성능 확인

4. GridSearchCV 객체의 cv_results_ 속성으로 map_depth에 따른 예측성능 변화 확인
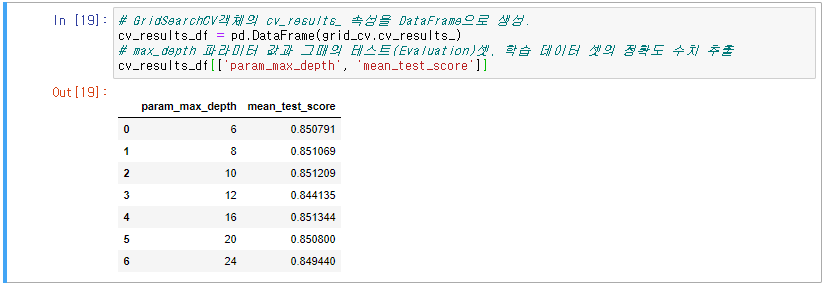
5. max_depth 값에 따른 정확도 확인

6. max_depth, min_samples_split 값의 변화에 따른 정확도 확인

7. grid_cv의 best_estimator_ 속성(max_depth=8, min_samples_split =16)으로 예측 수행

8. 결정 트리에서 각 피처의 중요도 시각화, feature_importances_ 속성 활용

'코딩 > Machine Learning' 카테고리의 다른 글
| 7. 분류(Classification)_3 (0) | 2020.12.13 |
|---|---|
| 6. 분류(Classification)_2 (2) | 2020.12.13 |
| 4. 평가(분류 평가) (1) | 2020.11.29 |
| 3. Scikit-learn(사이킷런) (0) | 2020.10.24 |
| 2. Pandas (1) | 2020.09.12 |




댓글