권철민 저, '파이썬 머신러닝 완벽 가이드', 2019.02.28
내 맘대로 요약 공부 중(문제시 비공개 및 삭제)
최초 작성일 2020.12.13
6.1 앙상블 학습(Ensemble Learning)
- 여러 개의 분류기(Classifier)를 생성하고 그 예측을 결합하여 보다 정확한 최종 예측을 도출하는 방식
- 보팅(Voting), 배깅(Bagging), 부스팅(Boosting), 스태킹(Stacking) 등
| 보팅(Voting) | 서로 다른 알고리즘을 가진 분류기를 결합 |
| 배깅(Bagging) | 데이터 샘플링을 서로 다르게 추출하여 학습한 같은 유형의 분류기를 결합 / 랜덤 포레스트 등 |
| 부스팅(Boosting) | 여러 개의 분류기가 순차적으로 학습 및 예측, 예측이 틀렸다면 다음 분류기에 가중치(Weight)를 부여 Gradient Boost / XGBoost / LightGBM 등 |
- 부트스트래핑(Bootstraping): 개별 분류기에 서로 다른 데이터를 샘플링하는 방식, 복원 추출
6.2 보팅(Voting) - 하드 보팅(Hard Voting), 소프트 보팅(Soft Voting)
- 하드 보팅(Hard Voting): 다수결 원칙, 예측 값 중 다수의 분류기가 예측한 값을 최종 선정
- 소프트 보팅(Soft Voting): 평균, 예측 값을 평균하여 확률이 높은 값을 최종 선정
- sklearn의 VotingClassifier 이용, 로지스틱 회귀와 KNN을 기반으로 하는 보팅 분류기 실습
- 위스콘신 유방암 데이터 세트 활용

- 보팅으로 여러 개의 분류기를 결합한다고 무조건 성능이 좋아지지 않음
- 데이터의 특성과 분포 등 다양한 요건에 따라 결과는 천차만별
- 앙상블 기법으로 수십~수천 개의 알고리즘을 결합하여 랜덤 포레스트의 과적합을 방지할 수 있음
6.3 랜덤 포레스트(Random Forest)
- 여러 개의 결정 트리 분류기가 전체 데이터에서 배깅 방식으로 각각 데이터를 샘플링해 개별학습 후 보팅을 통해 예측을 결정
- 부트스트래핑(Bootstraping) 방식
- sklearn의 RandomForestClassifier 이용, 사용자 행동 인식 데이터 세트 활용

- 랜덤 포레스트 하이퍼 파라미터 및 튜닝
| 파라미터 명 | 설명 |
| n_estimators | 랜덤포레스트에서 결정 트리 개수, Default = 10, 적정한 값 선정 필요 |
| max_features | 최적의 분할을 위해 고려할 최대 피처 수, Default = sqrt, sqrt(전체피처 수) |
| max_depth | 트리의 최대 깊이 설정(과적합 방지), Default=None, 적정한 값 선정 필요 |
| min_samples_leaf | 리프 노드가 되기 위한 최소한의 샘플 데이터 수(과적합 방지) |
- GridSearchCV 활용, GridSearchCV 생성 시 n_jobs=-1 파라미터를 추가하면 모든 CPU 코어를 사용



6.4 GBM(Gradient Boosting Machine)
- 여러 개의 분류기가 순차적으로 학습 및 예측하며, 잘못 예측한 경우에 가중치(Weight)를 부여하면서 학습하는 방식
- 경사 하강법(Gradient Descent)으로 가중치를 업데이트, 회귀에서 매우 중요
- 분류의 실제 결과값 = y, 피처 = x1, x2... xn, 예측 함수 = F(x)일 때
오류 h(x) = y - F(x)
h(x)를 최소화하는 방향으로 가중치를 업데이트
- sklearn의 GradientBoostingClassfier 이용, 사용자 행동 인식 데이터 세트 활용

- 랜덤포레스트에 비해 성능이 좋지만 학습 시간이 오래 걸림
- GBM 하이퍼 파라미터 및 튜닝
| 파라미터 | 설명 |
| loss | 경사하강법의 비용 함수, Default = 'deviance' |
| learning_rate | GBM이 학습할 때마다 적용하는 학습률, 0~1, 작을수록 업데이트 값이 적고 성능은 좋아지나 오래걸림 n_estimators와 상호 보완적으로 조합, learning_rate를 작게 하고 n_estimators를 크게, 오래걸림 |
| n_estimators | 분류기 개수, 많을수록 예측 성능이 어느정도 까지는 좋아지나 오래걸림, Default = 100 |
| subsample | 학습에 사용하는 데이터 샘플링 비율, Default = 1, 과적합이 우려 시 1보다 작게 설정(1=전체에서 샘플링) |

- 수행 시간이 오래 걸린다는 단점
6.5 XGBoost(eXtra Gradient Boost)
- GBM의 단점인 느린 수행 시간 및 과적합 규제의 부재 등의 문제를 해결
- 병렬 CPU 환경에서 사용 가능
- 분류, 회귀 영역에서 뛰어난 성능
- Tree Pruning(가지치기), 더 이상 이득이 없는 분할을 가지치기해서 분할 수를 줄여 성능 향상
- 자체 교차검증으로 GridSearchCV를 적용할 필요가 없음
- 결손값을 자체 처리할 수 있는 기능 적용
- 파이썬 래퍼 XGBoost 모듈 설치(원래 XGBoost는 독자적 모듈이라 sklearn에 적용이 안됐으나.. 해결됨)
Command창 관리자 권한으로 실행, conda install -c anaconda py-xgboost

- 파이썬 래퍼 XGBoost 하이퍼 파라미터(일반 파라미터, 부스터 파라미터, 학습 태스크 파라미터)
| 일반 파라미터 | 설명 |
| booster | gbtree(tree based model) 혹은 gblinear(linear model), Default = gbtree |
| silent | 출력 메세지를 나타내고 싶지 않을 경우 1, Default = 1 |
| nthread | CPU의 실행 스레드 개수 조정, Default = 전체 thread 사용 |
| 부스터 파라미터 | 설명 |
| eta[learning_rate] | 부스팅 중 업데이트되는 학습률, 보통 0.01 ~ 0.2 사이값 지정, Default=0.3 |
| num_boost_rounds | GBM의 n_estimators와 동일 |
| min_child_weight | GBM의 min_samples_leaf와 유사, 과적합 방지 |
| gamma[min_split_loss] | 트리의 리프 노드를 추가적으로 나눌지 결정하는 최소 손실 감소값, 이 값보다 손실(loss)이 더 크면 노드를 분리 즉, 값이 클수록 보수적인 트리가 형성 |
| max_depth | 트리 기반 알고리즘의 max_depth와 동일, 보통 3 ~ 10 사이값 지정, Default=6 |
| sub_sample[subsample] | GBM의 subsample과 동일, 과적합방지 데이터 샘플링 비율, 보통 0.5 ~ 1 사이값 지정, Default=1 |
| colsample_bytree | GBM의 max_features와 유사, 피처가 매우 많을 경우 과적합 조정에 사용, Default =1 |
| lambda[reg_lambda] | L2 Regularization, 피처가 많을 경우 적용 검토, 값이 클수록 과적합 방지 |
| alpha[reg_alpha] | L1 Regularization, 피처가 많을 경우 적용 검토, 값이 클수록 과적합 방지 |
| scale_pos_weight | 비대칭 클래스로 구성된 데이터의 균형을 유지하기 위한 파라미터 ,Default=1 |
| 학습 태스크 파라미터 | 설명 |
| objective | 최소값을 가져야할 손실함수 정의, 이진분류/다중분류에 따라 다름 |
| binary:logistic | 이진 분류일 때 적용 |
| multi:softmax | 다중 분류일 때 적용, num_class 파라미터를 지정해야 함 |
| multi:softprob | 다중 분류일 때 적용, 개별 레이블 클래스에 해당하는 예측 확률 반환 |
| eval_metric | 검증에 사용되는 함수, 보통 회귀: rmse, 분류: error rmse, mae, logloss, error, merror, mlogloss, auc 등... |
- 과적합 발생 시 고려사항
- eta 값을 낮춤(0.01 ~ 0.1), 값을 낮출 경우 num_round(또는 n_extimators)는 높임
- max_depth 값을 낮춤
- min_child_weight 값을 낮춤
- gamma 값을 낮춤
- subsample, colsample_bytree 값 조정(트리가 너무 복잡하게 생성되지 않게)
- 위스콘신 유방암 데이터 세트 활용



- XGBoost는 데이터를 DMatrix로 변환하여 사용해야 함


- early_stopping_rounds 파라미터를 사용할 경우 반드시 eval_set, eval_metric 필요
- 반복마다 eval_set로 지정된 데이터 세트에서 eval_metric의 평가 지표로 예측 오류를 측정


- 예측 평가하기


- 시각화(XGBoost에 내장된 plot_importance API 활용)

- 시각화(XGBoost에 내장된 to_graphviz API 활용)
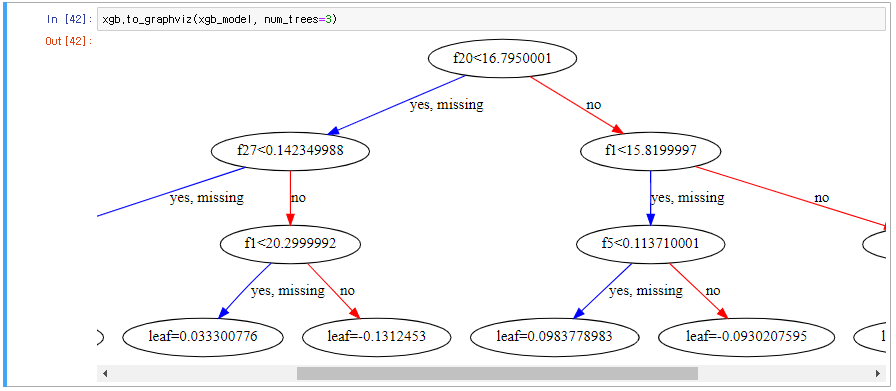
- XGBoost의 cv() API로 교차검증 가능

| 파라미터 | 설명 |
| params | 부스터 파라미터들, 위 설명 |
| dtrain | DMatrix, 위 설명 |
| num_boost_round | 부스팅 반복 횟수 |
| nfold | CV 폴드 개수 |
| stratified | CV 수행 시, 층화 표본 추출 수행 여부(Stratified Sampling) |
| metrics | CV 수행 시, 모니터링할 성능 평가 지표 |
| early_stopping_rounds | 조기 중단 활성화 여부, 반복 횟수 지정 |
- XGBoost 하이퍼 파라미터 튜닝(베이즈 최적화)
- 지금까지 해온 격자 탐색(Grid Search)과 더불어 실전에 자주 쓰이는 베이즈 최적화(Bayesian Optimization)

- statkclee.github.io/model/model-python-xgboost-hyper.html
model-python-xgboost-hyper
3가지 초모수 튜닝¶ 일반적으로 초모수(Hypter Parameter)를 튜닝하는 방식은 격자 탐색(Grid Search), 임의 탐색(Random Search), 베이즈 최적화(Bayesian Optimization) 방식이 많이 사용된다. 가장 기본적인 격자
statkclee.github.io
- 사이킷런 XGBoost 적용(분류 XGBClassifier, 회귀 XGBRegressor), 위스콘신 유방암 데이터 세트 활용




- 사이킷런 XGBoost 시각화(plot_importance() API 활용)

'코딩 > Machine Learning' 카테고리의 다른 글
| 8. 회귀(Regression)_1 (0) | 2020.12.27 |
|---|---|
| 7. 분류(Classification)_3 (0) | 2020.12.13 |
| 5. 분류(Classification)_1 (0) | 2020.12.10 |
| 4. 평가(분류 평가) (1) | 2020.11.29 |
| 3. Scikit-learn(사이킷런) (0) | 2020.10.24 |




댓글