권철민 저, '파이썬 머신러닝 완벽 가이드', 2019.02.28
내 맘대로 요약 공부 중(문제시 비공개 및 삭제)
최초 작성일 2020.10.24
3.1 Scikit-learn(사이킷런) 이란?
- 파이썬에서 머신러닝을 위한 가장 쉽고 효율적인 라이브러리
- 오랜 기간 개발되어 라이브러리의 성숙도가 높고 매우 많은 환경에서 사용 중
- 현재는 Tensorflow, Keras 등이 대세
- Anaconda 설치 시 기본 라이브러리에 포함되어 있음
- pip install scikit-learn
3.2 기본예제(붓꽃 품종 예측)
- 분류(Classification)는 지도학습(Supervised Learning) 방법 중 하나
- 학습데이터로 모델을 학습시킨 후 별도의 테스트데이터로 검증 및 분류
- sklearn.datasets → 자체 제공 데이터 세트(load_iris 적용)
- sklearn.tree → 트리 기반 ML 알고리즘 모듈(Decision Tree 적용)
- skleran.model_selection → 데이터 분리 및 최적 하이퍼파라미터 평가 모듈(train_test_split 적용)
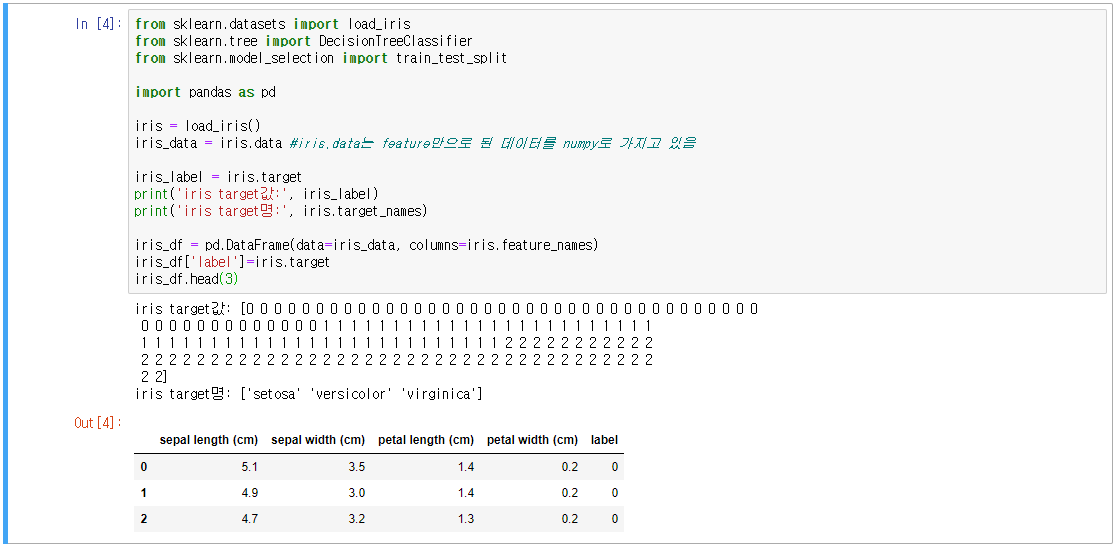
- 데이터 나누기(Training Data, Test Data)
- test_size, 전체 데이터세트 중 Test Data 비율
- random_state, 난수발생으로 데이터를 무작위로 섞음(수는 어떤 값을 지정해도 상관 없음)

- 학습모델 객체 생성 및 학습


- Test Data를 사용하여 모델의 정확도 예측

- 프로세스: 데이터 분리 → 모델 선정 → 모델 학습 → 모델 평가(정확도 예측)
3.3 scikit-learn(사이킷런) 기반 프레임워크
- scikit-learn(사이킷런)은 지도학습의 분류(Classification), 회귀(Regression)를 fit(), predict()로 구현하고 있음
- 지도학습의 모든 알고리즘을 구현한 클래스를 Estimator로 통칭
- cross_val_score() 등의 evaluation 함수, GridSearchCV 등의 하이퍼 파라미터 튜닝 클래스는 Estimator를 인자로 받음
- scikit-learn(사이킷런)은 비지도학습의 차원 축소, 클러스터링, 피처 추출 등을 fit(), transform()로 구현하고 있음
- scikit-learn(사이킷런)의 주요 모듈
| 분류 | 모듈명 | 설명 |
| 예제 데이터 | sklearn.datasets | 사이킷런에 내장된 데이터세트 |
| 피처 | sklearn.preprocessing | 전처리에 필요한 다양한 기능(인코딩, 정규화, 스케일링) |
| sklearn.feature_selection | 피처를 우선순위대로 셀렉션하는 다양한 기능 | |
| sklearn.feature_extraction | 데이터의 벡터화된 피처를 추출하는 기능 | |
| 피처 처리 & 차원 축소 | sklearn.decomposition | 차원 축소와 관련한 알고리즘 지원 |
| 데이터 분리, 검증 & 파라미터 튜닝 | sklearn.model_selection | 학습/검증 데이터 분리, 그리드서치를 통한 최적 파라미터 추출 등 |
| 평가 | sklearn.metrics | 분류, 회기, 클러스터링에 대한 다양한 성능 측정 방법 지원 |
| ML 알고리즘 | sklearn.ensemble | 앙상블 알고리즘 지원 |
| sklearn.linear_model | 선형 회귀, 릿지, 라쏘 등 회귀관련 알고리즘, SGD 알고리즘 지원 | |
| sklearn.naive_bayes | 나이브 베이즈 알고리즘 지원 | |
| sklearn.neighbors | 최근접 이웃 알고리즘(K-NN) 등 지원 | |
| sklearn.svm | 서포트 벡터 머신 알고리즘 지원 | |
| sklearn.tree | 의사 결정 트리 알고리즘 지원 | |
| sklearn.cluster | 비지도 클러스터링 알고리즘 지원 | |
| 유틸리티 | sklearn.pipeline | 피처 처리 등의 변환, ML 알고리즘 학습 및 예측 등을 함께 실행할 수 있는 유틸리티 지원 |
- 내장된 데이터세트
| API명 | 설명 |
| datasets.load_boston() | 회귀, 미국 보스턴 집 피처와 가격 데이터 세트 |
| datasets.load_breast_cancer() | 분류, 위스콘신 유방암 피처와 악성/음성 레이블 데이터 세트 |
| datasets.load_diabetes() | 회귀, 당뇨 데이터 세트 |
| datasets.load_digits() | 분류, 0~9 숫자 이미지 데이터 세트 |
| datasets.load_iris() | 분류, 붓꽃 피쳐 데이터 세트 |
| datasets.make_classifications() | 분류, 높은 상관도/불필요 속성/노이즈 효과 데이터 무작위 생성 |
| datasets.make_blobs() | 클러스터링, 군집 지정 개수에 따른 클러스터링을 위한 데이터 생성 |
- fetch 계열은 데이터가 내장되어있지 않고, 따로 내려 받아 scikit_learn_data 디렉터리에 저장 후 불러들이는 데이터
| API명 | 설명 |
| fetch_covtype() | 회귀 분석용 토지 조사 자료 |
| fetch_20newsgroups() | 뉴스 그룹 텍스트 자료 |
| fetch_olivetti_faces() | 얼굴 이미지 자료 |
| fetch_lfw_people() | 얼굴 이미지 자료 |
| fetch_lfw_pairs() | 얼굴 이미지 자료 |
| fetch_rcv1() | 로이터 뉴스 말뭉치 자료 |
| fetch_mldata() | ML 웹사이트 다운로드 |
- 데이터 세트는 딕셔너리 형태로 저장되어 있음
- 키는 일반적으로 data, target, target_name, feature_names, DESCR로 구성
- data: 데이터, target: 분류 시 레이블 값, 회귀 시 결과값 / Type: 넘파이(ndarray)
- target_name: 개별 레이블의 이름, feature_name: 피처의 이름 / Type: 리스트(list)
- DESCR: 데이터 세트, 피처의 설명 / Type: 스트링(string)
- 데이터 세트 예시


3.4 Model Selection 모듈
- Training/Test Data 분리, train_test_split()
- 데이터 나누기(Training Data, Test Data)
- test_size, 전체 데이터세트 중 Test Data 비율
- random_state, 난수발생으로 데이터를 무작위로 섞음(수는 어떤 값을 지정해도 상관 없음)

- 교차검증, 데이터 편중으로 인한 모델의 과적합(Overfitting)을 방지하기 위해 별도의 세트로 구성된 학습데이터와 검증
데이터로 학습과 평가를 수행하는 것
- K 폴드 교차 검증, K개의 데이터 폴드를 만들어 K번만큼 학습과 검증 평가를 반복적으로 수행하는 방법


- Stratified K 폴드 검증, 데이터 분포가 불균형할 경우 사용하는 교차 검증 방법
- K 폴드 검증방법과 거의 비슷하며, 레이블 데이터를 Split() 함
- 사실상 scikit-learn(사이킷런)에서 분류 시, Stratified K 폴드 검증 방법을 사용하는 게 좋음

- cross_val_score(), 간편한 교차 검증 방법
- (estimator, X, y=None, scoring=None, cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch='2*n_jobs')
- estimator = Classifier 또는 Regressor Class를 의미
- X: feature 데이터 세트, y: label 데이터 세트, scoring: 성능지표 측정값, cv: 교차 검증 폴드 수

- GridSearchCV, 교차 검증 & 하이퍼 파라미터 튜닝
- (estimator, param_grid, scoring=None, cv=None, refit=True)
- estimator = Classifier 또는 Regressor Class를 의미
- param_grid: 최적의 파라미터를 찾기위한 딕셔너리 값, scoring: 성능지표 측정값, cv: 교차 검증 폴드 수
- refit: True가 Default이며, 최적의 파라미터를 찾은 후 해당 파라미터로 모델을 재학습 시킴


3.5 데이터 전처리(Data Preprocessing)
- 결손값(NULL)을 허용하지 않음, 결손치를 다른 값으로 변환해야 함(원본 데이터를 훼손하지 않는 선에서)
- scikit-learn(사이킷런)은 문자열 값을 입력 값으로 허용하지 않음, 벡터화 혹은 숫자형으로 변환해야 함
- 레이블 인코딩(Label Encoding), feature를 코드형 숫자로 변환
- LabelEncoder

- 원-핫 인코딩(One-Hot Encoding), feature값에 따라 해당하는 값만 1로 나머지는 0으로 변환
- 인코딩 전, 모든 문자열 값이 숫자형 값으로 변환되어야 함
- OneHotEncoder

- Pandas의 get_dummies()를 이용할 경우 숫자형으로 변환하지 않고 OneHotEncoder 변환 가능

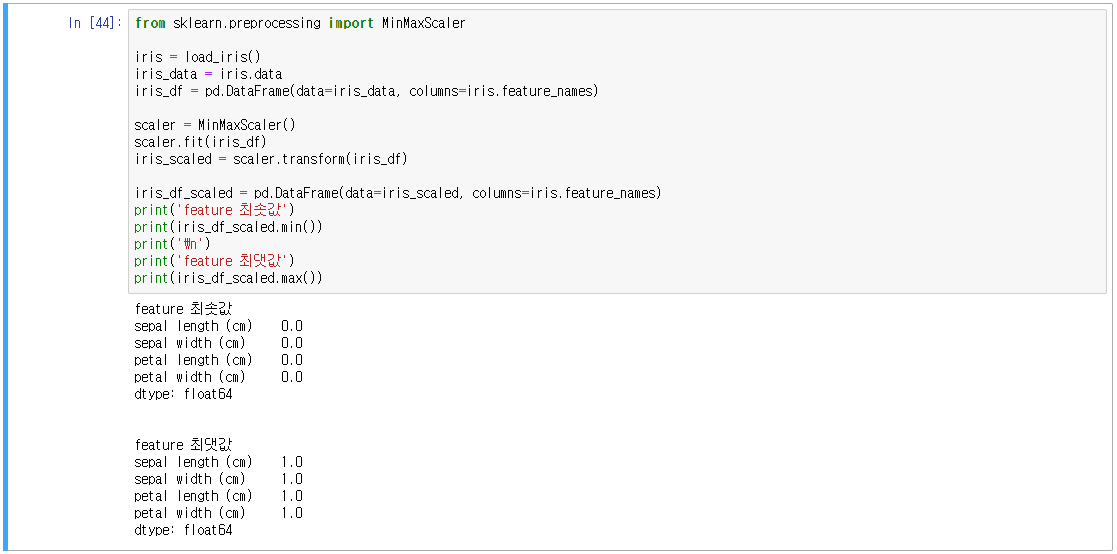
- 피처 스케일링(Feature Scaling), 서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 것
- 표준화(Standardization), 정규화(Normalization)
- scikit-learn(사이킷런)은 StandardScaler, MinMaxScaler 기능 지원

3.6 실전예제, 타이타닉 생존자 예측







'코딩 > Machine Learning' 카테고리의 다른 글
| 5. 분류(Classification)_1 (0) | 2020.12.10 |
|---|---|
| 4. 평가(분류 평가) (1) | 2020.11.29 |
| 2. Pandas (0) | 2020.09.12 |
| 1. Numpy (0) | 2020.09.08 |
| Anaconda3로 Tensorflow-gpu 설치하기 (0) | 2020.03.29 |




댓글