권철민 저, '파이썬 머신러닝 완벽 가이드', 2019.02.28
내 맘대로 요약 공부 중(문제시 비공개 및 삭제)
최초 작성일 2020.11.29
4.1 머신러닝 모델의 예측 성능 평가란?
- 머신러닝은 데이터 가공/변환, 모델 학습/예측, 평가(Evaluation) 프로세스로 구성
- 성능 평가 지표(Evaluation Metric)는 일반적으로 분류, 회귀에 따라 나뉨
- 분류에 대한 평가
- 회귀에 대한 평가는(5장에서 다룸)
- 분류의 성능 평가 지표(이진분류, 멀티분류)
- 정확도(Accuracy)
- 오차행렬(Confusion Matrix)
- 정밀도(Precision)
- 재현율(Recall)
- F1 스코어
- ROC AUC
4.2 정확도(Accuracy)
- 실제 데이터와 예측 데이터가 얼마나 같은지 판단하는 지표
- 이진 분류의 경우 데이터의 구성에 따라 성능을 왜곡할 수 있기 때문에, 정확도 하나만으로 성능을 평가하지 않음
- MNIST 데이터 세트를 사용하여 정확도의 문제 확인
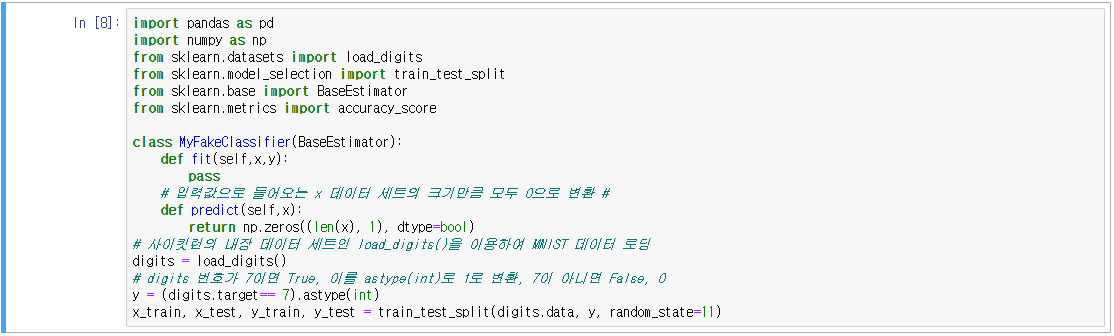

- 단순하게 모든 것을 0으로 예측해도 정확도가 90%가 나온다는 것은, 정확도만으로 성능을 평가하는 것은 어렵다는 것
4.3 오차행렬(Confusion Matrix)
- 학습된 분류 모델이 예측을 수행하면서 얼마나 헷갈리고 있는지 보여주는 지표
- 이진 분류의 예측 오류가 얼마인지, 어떤 유형의 오류가 발생하고 있는지 보여줌

- sklearn의 confusion_matrix() API 활용

- TN(예측: 7이 아닌 Digits, 실제: 7이 아닌 Digits)이 405건, FN(예측: 7이 아닌 Digits, 실제: 7인 Digits) 45건
- 불균형 데이터에서는(ex. 암 진단 or 보험사기 예측 등) Positive 데이터 건수가 매우 적기 때문에, Negative로 예측 정확도가 높아지는 경향이 있음
- 불균형 데이터 분류 모델의 성능을 측정하기에는 적절하지 않을 수 있음
4.4 정밀도와 재현율(Precision And Recall)
- Positive 데이터 세트의 예측 성능에 초점을 둔 평가 지표
- 정밀도 = TP / (FP + TP), 예측을 Positive로 한 것 중에 실제 값이 Positive인 데이터 비율
- 재현율 = TP / (FN + TP), 실제 값이 Positive인 것 중에 예측값이 Positive인 데이터 비율
- 재현율은 민감도(Sensitivity) 혹은 TPR(True Positive Rate)와 동의어
- 이진 분류 모델의 특성에 따라 정밀도와 재현율 중 더 중요한 지표를 선택하면 됨(일반적으로는 재현율이 중요)
- 재현율이 중요한 경우, 실제 Positive 양성인 데이터 예측을 Negative로 잘못 판단하게 되면 큰 영향이 있는 경우
- 정밀도가 중요한 경우, 실제 Negative 음성인 데이터 예측을 Positive로 잘못 판단하게 되면 큰 영향이 있는 경우
- 가장 좋은 성능은 정밀도와 재현율 모두 높은 수치를 나타내는 것
- sklearn의 precision_score(), recall_score0 API 활용


- 정밀도와 재현율을 좀 더 강화할 수 있는 방법은?
4.5 정밀도/재현율 트레이드 오프
- 분류 결정 임계값을 조절하여 정밀도와 재현율의 성능 수치를 상호 보완적으로 조정할 수 있음
- 일반적인 이진 분류에서는 임계값을 0.5, 즉 50%로 정하고 이보다 크면 Positive, 작으면 Negative
- sklearn의 predict_proba(), 개별 데이터별로 예측 확률을 반환, 학습이 완료된 Classifier 객체에서 호출 가능
(테스트 피처 데이터 세트를 파라미터로 입력해주면 테스트 피처 레코드의 개별 클래스 예측 확률을 반환)

- 사이킷런의 정밀도/재현율 트레이드 오프 구현
- sklearn의 Binarizer 적용, Binarizer(threshold=N) N보다 작거나 같으면 0, 크면 1로 반환



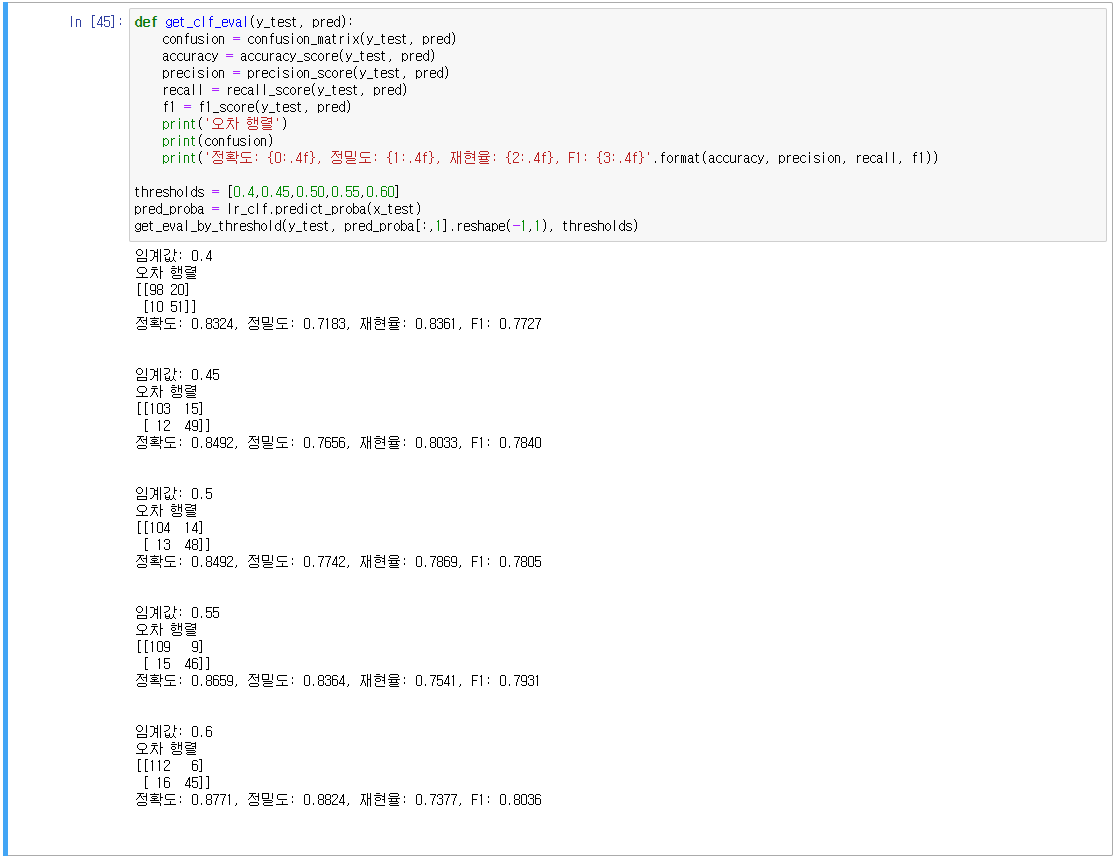
- 분류 결정 임계값은 Positive 예측값을 결정하는 확률의 기준
- 0.5 → 0.4, Positive 예측을 더욱 너그럽게 하므로 True 값이 많아지게 됨

- 임계값이 0.45일 때, 재현율을 향상 시키면서 정밀도가 가장 조금 감소함
- sklean의 precision_recall_curve() API 적용, 입력 파라미터: 실제 데이터 세트, Positive일 때의 예측 확률,
반환 파라미터: 임계값별 정밀도 값, 임계값별 재현율 값


- 정밀도와 재현율은 상황에 따라 수치 조작이 가능함. 숫자 놀음에 불과할 수 있음.
- 정밀도와 재현율이 적절하게 조합돼 분류의 종합적인 성능평가에 사용될 수 있는 평가 지표 필요
4.6 F1 스코어

- 어느 한쪽으로 치우치지 않는 수치를 나타낼 때 상대적으로 높은 값을 보임
- sklearn의 f1_score() API 적용

4.7 ROC(Receiver Operation Characteristic) 곡선과 AUC
- ROC 곡선(Receiver Operation Characteristic Curve), 수신자 판단 곡선
- ROC 곡선은 FPR(False Positive Rate)이 변할 때 TPR(True Positive Rate)이 어떻게 변하는지 나타내는 곡선
- X축 : FPR, Y축 : TPR
- TPR과 TNR(True Negative Rate)
- TPR(민감도)은 실제값 Positive가 정확히 예측돼야 하는 수준을 나타냄(질병이 있는 사람은 질병이 있는 양성)
- TNR(특이성)은 실제값 Negative가 정확히 예측돼야 하는 수준을 나타냄(질병이 없는 사람은 질병이 없는 음성)

- ROC 곡선을 그리는 방법: 분류 결정 임계값을 1부터 0까지 거꾸로 변화시키면서 곡선을 그리면 됨
- sklearn의 roc_curve() API 적용
- 입력: y_true 실제 클래스 값, y_score predict_prob()의 반환 값에서 Positive 칼럼의 예측 확률
- 결과: FPR, TPR, thresholds


- ROC 곡선은 FPR과 TPR의 변화를 보는데 이용
- 실제 분류 모델 성능 지표로 사용되는 것은 ROC 곡선 면적에 기반한 AUC값
- AUC(Area Under Curve), ROC 곡선 밑의 면적을 구한 것으로 1에 가까울수록 좋은 수치, 보통 분류는 0.5를 가짐

4.8 피마 인디언 당뇨병 예측
- www.kaggle.com/uciml/pima-indians-diabetes-database
Pima Indians Diabetes Database
Predict the onset of diabetes based on diagnostic measures
www.kaggle.com



- 실제 당뇨병 환자를 예측하지 못하면 문제가 될 수 있으므로 재현율 성능을 올려야 함

- 이럴 경우, 데이터를 다시 점검





- 재현율 개선 필요. 분류 결정 임계값을 변화시키면서 확인


4.9 결론
- 오차행렬은 Negative와 Positive 값을 가지는 실제 값과 예측 값의 True, False에 따라 예측 성능을 평가
- 정확도, 정밀도, 재현율은 TN, FP, FN, TP 값을 다양하게 결합해 만들어지며 모델의 오류 형태를 알 수 있음
- 정밀도, 재현율은 Positive 데이터 세트의 예측 성능에 좋음
- 정밀도, 재현율이 특별히 강조되어야 할 경우, 분류 결정 임계값(Threshold)을 조정함
- F1 스코어는 정밀도와 재현율을 결합한 평가 지표, 어느 한쪽으로 치우치지 않을 때 높은 값을 나타냄
- ROC-AUC는 이진 분류의 성능 평가에 가장 많이 사용, AUC는 ROC의 아래 면적이며 1에 가까울수록 좋음
'코딩 > Machine Learning' 카테고리의 다른 글
| 6. 분류(Classification)_2 (0) | 2020.12.13 |
|---|---|
| 5. 분류(Classification)_1 (0) | 2020.12.10 |
| 3. Scikit-learn(사이킷런) (0) | 2020.10.24 |
| 2. Pandas (0) | 2020.09.12 |
| 1. Numpy (0) | 2020.09.08 |




댓글