권철민 저, '파이썬 머신러닝 완벽 가이드', 2019.02.28
내 맘대로 요약 공부 중(문제시 비공개 및 삭제)
최초 작성일 2021.1.1
9.1 다항 회귀와 과적합/과소적합
- 독립변수(feature)와 종속변수(target)의 관계가 일차방정식(단항식)이 아닌, 2차, 3차 등 다항식으로 표현되는 회귀
- Y = a + bX1 + cX2 + dX1X2 …(Y: 종속변수 / X1, X2: 독립변수 / a, b, c, d: 회귀계수)
- 다항 회귀는 선형 회귀임!
- 회귀에서 선형/비선형을 나누는 기준은 회귀 계수가 선형/비선형인지에 따름(독립변수의 선형/비선형과 무관)
- sklearn은 다항 회귀를 위한 클래스는 없으므로, 비선형 함수를 선형 모델에 적용시키는 방법을 사용
- sklearn의 PolynomialFeatures 클래스 활용, Polynomial(다항식) 피처로 변환
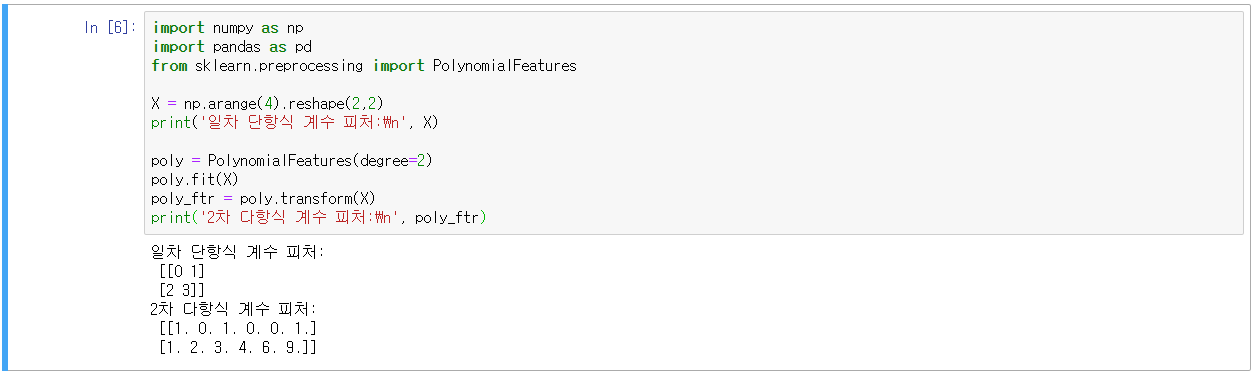

- ①일차 단항식 계수를 삼차 다항식 계수로 변환하고, ②이를 선형 회귀에 적용하면 다항 회귀로 구현

- sklearn의 Pipeline 객체를 활용하여 한번에 다항 회귀를 구현할 수 있음

9.2 과소적합 및 과적합(Feat. 다항 회귀)
- 다항식의 차수가 높아질수록 과적합 문제가 심함
- 차수가 높아질수록 학습 데이터에만 의존하기 때문
- 학습 데이터: 30개의 임의의 데이터 X, target: y

- 다항식 차수별(1, 4, 15) 예측 결과 비교
- cross_val_score, MSE 계산을 통한 성능 비교


- 맨 오른쪽, 15차수 회귀 예측을 할 경우 심하게 과대적합되어 MSE값이 비정상적으로 크고 예측 그래프가 다름
- 적정 차수의 회귀 예측 필요(실제 회귀할 때도 5차~6차 이상 넘어가면 과대적합 되는경우가 많음)
- 편향-분산 트레이드오프(Bias-Variance Trade off)
- Degree1: 고편향(High Bias), Degree15: 고분산(High Variance)

- 일반적으로 편향과 분산은 반비례관계로 한쪽이 높으면 한 쪽이 낮아지는 경향
- 편향이 높으면 전체 오류가 높음
- 편향이 낮으면 분산이 높아지고 전체 오류가 낮아짐
- 편향이 Optimal 지점을 넘어서 더 낮아지면 전체 오류가 증가함
- 즉, 편향과 분산이 서로 트레이드오프를 유지하며 오류 값이 최소가 되는 모델을 만드는 것이 중요
9.3 규제(Regularization) 선형 모델 - 릿지, 라쏘, 엘라스틱넷
- 회귀 모델은 데이터에 적합해야 하며, 회귀 계수가 지나치게 커지는 것을 주의해야 함(고편향 방지)
- 비용 함수는 RSS(실제 값과 예측값의 차이)를 최소화하며 회귀계수 크기를 제어해야 함
- 비용함수 목표 = Min(RSS + alpha*|W|)
- alpha를 조절함으로써 회귀 계수의 크기(|W|)를 조절할 수 있음 → 규제(Regularization)
- L1 규제 → alpha*|W|^2에 페널티를 부여하는 방식(라쏘)
- L2 규제 → alpha*|W|에 패널티를 부여하는 방식(릿지)
- L1 규제 + L2 규제 → 엘라스틱넷
① L2규제(릿지 Ridge)
- sklearn의 Ridge
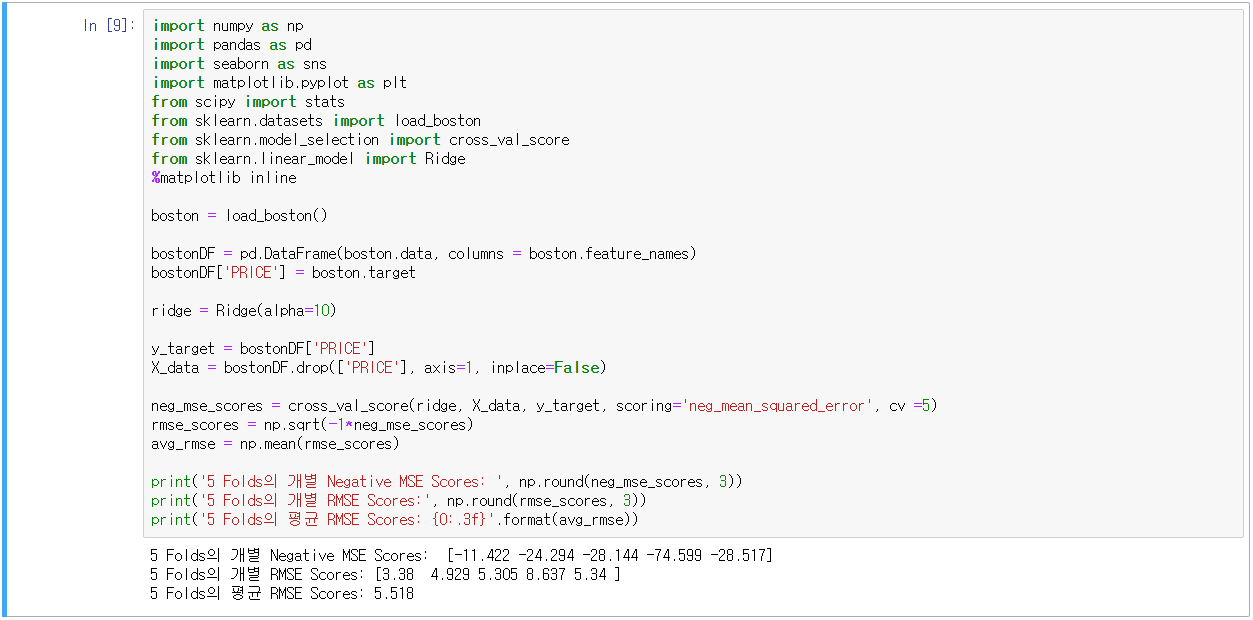

- alpha값의 변화에 따른 피처의 회귀 계수 값 시각화(회귀 계수를 Ridge의 coef_ 속성 추출하여 Series화)

- alpha값을 증가시킬수록 NOX 피처의 회귀 계수가 작아지는 것을 확인
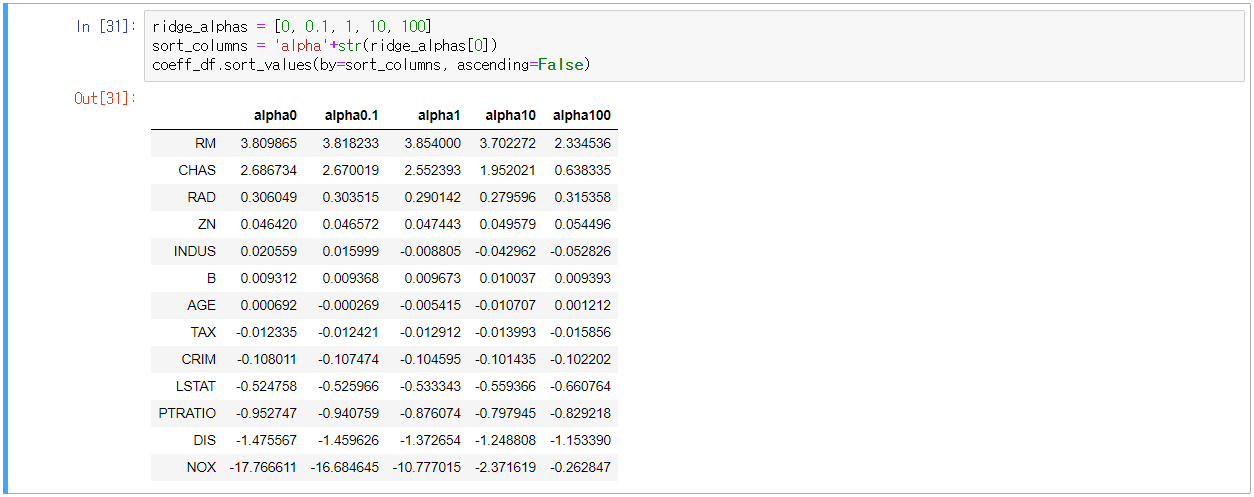
- L2 규제의 한가지 특징적인 것은 회귀 계수를 0으로 만들지 않는다는 것
② L1규제(라쏘 Lasso)
- L2 규제와 다르게 불필요한 회귀 계수는 0으로 만들고 제거, 즉 적절한 피처만 선택
- alpha값을 변화시키며 RMSE와 각 피처의 회귀 계수를 확인
- sklearn의 Lasso
- get_linear_reg_eva()
- 입력: 회귀모델의 이름, alpha 리스트, 피처 데이터 세트, target 데이터 세트
- 출력: alpha값에 따른 RMSE 출력, 회귀계수 DataFrame화


③ L1+L2규제(엘라스틱넷, ElasticNet)
- L1규제의 상관관계가 높은 피처를 제외한 나머지는 0으로 바꾸고, 회귀 계수의 급변을 방지하기 위해 L2규제를 적용
- 유일한 단점은 수행시간이 길다는 것
- sklearn의 ElasticNet(주요 파라미터: alpha = a + b, l1_ratio = a / (a + b))
- ElasticNet의 규제는 a*L1 + b*L2로 정의(a: L1의 alpha, b: L2의 alpha)
- 예제에서는 l1_ration는 0.7로 고정

- 선형 회귀 모델을 위한 데이터 변환(데이터 스케일링 및 정규화)
- StandardScaler 클래스를 이용해 평균이 0, 분산이 1인 표준 정규화 수행
- MinMaxScaler 클래스를 이용해 최솟값이 0, 최댓값이 1인 정규화 수행
- 1,2번 후 성능 향상이 없을 경우 다시(Re) 다항 특성을 적용하여 데이터 변환
- 로그 변환, 원래 값에 log 함수를 적용 (실제 선형 회귀에서 대부분 쓰임)
- get_scaled_data()
- 입력: 스케일링/정규화 method 인자 선택(StandardScaler, MinMaxScaler, Log), 차수(degree)


- alpha:0.1 → Log None, alpha:1 → MinMax 2, alpha:10 → Log None, alpha:100 → Standard 2
- 일반적으로 데이터 분포가 심하게 왜곡되어 있을 경우 로그 변환을 추천
9.4 로지스틱 회귀(Logistic Regression)
- 시그모이드(Sigmoid) 함수의 최적선을 찾아 반환 값을 확률로 표현 및 결정
- 선형 회귀 방식을 기반으로 시그모이드 함수를 이용해 분류를 수행
- 시그모이드 함수( y = 1/(1+e^(-x))

- 항상 0~1 사이 값을 반환
- 위스콘신 유방암 데이터를 활용하여 암 여부 판단(분류)


- 규제를 적용하여 최적의 파라미터를 찾아보자(GridSearchCV 활용)

'코딩 > Machine Learning' 카테고리의 다른 글
| 11. 차원 축소(Dimension Reduction) (0) | 2021.01.03 |
|---|---|
| 10. 회귀(Regression)_3 (0) | 2021.01.02 |
| 8. 회귀(Regression)_1 (0) | 2020.12.27 |
| 7. 분류(Classification)_3 (0) | 2020.12.13 |
| 6. 분류(Classification)_2 (0) | 2020.12.13 |




댓글