권철민 저, '파이썬 머신러닝 완벽 가이드', 2019.02.28
내 맘대로 요약 공부 중(문제시 비공개 및 삭제)
최초 작성일 2021.1.2
10.1 회귀 트리
- 회귀를 위한 트리를 생성하고 이를 기반으로 회귀 예측을 하는 것
- 분류 트리와의 다른 점은, 회귀 트리는 리프 노드에 속한 데이터 값의 평균값을 구해 회귀 예측값을 계산함
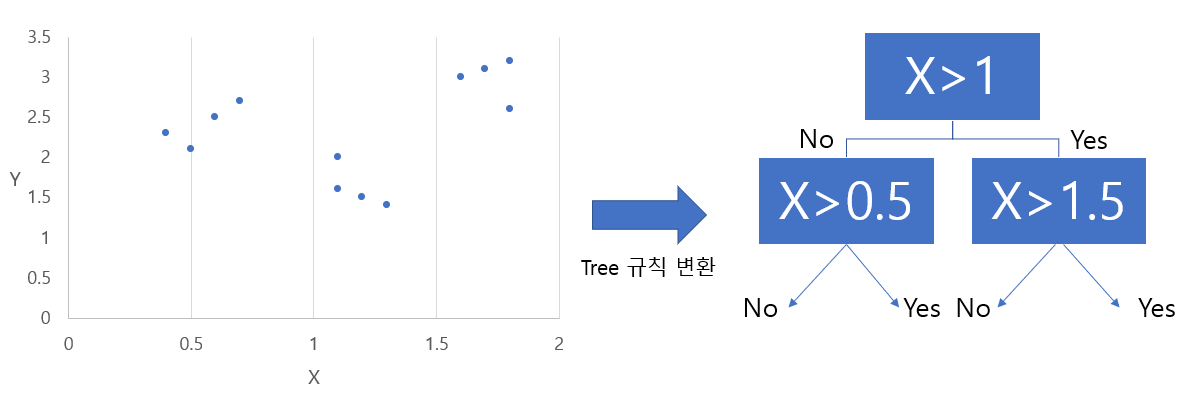

- 결정 트리, 랜덤 포레스트, GBM, XGBoost, LightGBM 등 트리 기반의 알고리즘은 분류와 회귀 가능
| 알고리즘 | 회귀 Estimator 클래스 | 분류 Estimator 클래스 |
| 결정 트리(Decision Tree) | DecisionTreeRegressor | DecisionTreeClassifier |
| Gradient Boosting | GradientBoostingRegressor | GradientBoostingClassifier |
| XGBoost | XGBRegressor | XGBClassifier |
| LightGBM | LGBMRegressor | LGBMClassifier |
- 랜덤 포레스트 회귀(RandomForestRegressor) 활용 보스턴 주택 가격 예측 수행

- get_model_cv_prediction() → 결정 트리, GBM, XGBoost, LightGBM 모두 이용


- 회귀 트리 Regressor는 회귀 계수를 제공하는 coef_ 속성이 없음
- feature_importances_ 속성을 활용하여 피처별 중요도 시각화

- 가장 밀접한 관계를 가지는 feature인 'RM'만 사용하여 선형 회귀와 결정 트리 회귀로 'PRICE' 예측 비교
- 100개의 데이터만 샘플링

- LinearRegression, DecisionTreeRegressor를 max_depth= 2, 7 비교
- 학습된 Regressor에 RM 값을 4.5~8.5 사이의 100개 테스트 데이터 세트 제공


10.2 회귀 실습 - 자전거 대여 수요 예측
- https://www.kaggle.com/c/bike-sharing-demand/data
Bike Sharing Demand
Forecast use of a city bikeshare system
www.kaggle.com


- Datetime Column의 object type(년-월-일 시:분:초)을 가공해야 함(년, 월, 일, 시간으로 각각 추출)

- 필요 없는 Column 삭제(datetime, casual, resistered)

- Kaggle에서 요구한 성능 평가 방법은 RMSLE(Root Mean Square Log Error)

- LinearRegression 활용하여 회귀 예측 진행

- 실제 값과 예측값의 차이 확인(Top 5개)

- 먼저 Target값 분포가 왜곡된 형태를 이루고 있는지 확인(Best: 정규분포 형태)
- pandas DataFrame의 hist() 속성 활용

- Target값의 분포가 왜곡된 것을 확인 → log변환(np.log1p() 사용)

- log변환된 값들은 np.expm1() 속성을 활용하여 원래 스케일로 변환하여 평가

- 각 피처의 회귀 계수 값 시각화

- 연도를 나타내는 카테고리형 피처지만, 숫자형으로 되어 있음
- 숫자형 카테고리 값을 선형 회귀에 사용할 경우 숫자형 값에 영향을 크게 받을 수 있으므로 원-핫 인코딩 적용해야 함
- pandas의 get_dummies() 활용
- year, month, hour, holiday, workingday, season, weather 변환

- 각 피처의 회귀 계수 시각화

- 회귀 트리를 이용한 성능 평가

10.3 회귀 실습 - 캐글 주택 가격: 고급 회귀 기법
- https://www.kaggle.com/c/house-prices-advanced-regression-techniques/data
House Prices - Advanced Regression Techniques
Predict sales prices and practice feature engineering, RFs, and gradient boosting
www.kaggle.com
- 데이터 전처리(Preprocessing)


- Target Data인 SalePrice 데이터의 분포도가 정규 분포인지 확인
- sns.distplot 활용

- Target 데이터 로그 변환(np.log1p() 변환 → expm1() 환원)

- NULL값이 지나치게 많은 PoolQC, MiscFeature, Alley, Fence, FireplaceQu 삭제
- 단순 식별자인 Id 삭제
- 숫자형 피처의 Null 값은 평균값으로 대체


- 문자형 피처를 원-핫 인코딩으로 변환(pandas의 get_dummies() 활용)
- get_dummies()는 자동으로 문자열 피처를 원-핫 인코딩 변환 및 NULL 값을 None 칼럼으로 대체함
- 원-핫 인코딩시 칼럼 개수 증가하므로 확인 필요

- 선형 회귀 모델 학습/예측/평가


- 피처별 회귀 계수 시각화


- 데이터 분할 문제인지 검증(분할하지 않고 진행)

- 하이퍼 파라미터 튜닝을 위한 별도의 함수 생성(print_best_params(model, params))

- 최적 alpha 값을 설정한 뒤, 다시 데이터를 분할하여 학습/예측/평가 및 시각화 수행

- 데이터 세트를 추가적으로 가공하여 모델 튜닝 진행(1. 피처 데이트 세트 분포도, 2. 이상치 데이터 처리)
- 모든 숫자형 피처의 데이터 분포도를 확인하여 왜곡 정도 확인
- scipy.stats 모듈의 skew() 함수로 쉽게 추출 가능
- skew() 적용 시 원-핫 인코딩이 적용된 숫자형 피처는 제외해야 함(원본으로 해야 한다는 소리)

- 왜곡 정도가 높은 피처를 로그 변환

- 다시, 문자열을 원-핫 인코딩 시키고 데이터 세트 분할, 최적 alpha값 및 RMSE값 파악 수행

- 최적 alpha 값으로 모델 학습/예측/평가 및 시각화

- 2개에서 회귀 계수가 높은 피처인 GrLivArea의 데이터 분포 확인(책에서는 3개가 GrLivArea)

- 위 그래프의 오른쪽 하단 2개의 점은 이상치 데이터가 확실(주거공간이 큰데 가격이 저렴함)
- GrLivArea >4000 & SalePrice <500000

- 다시 데이터 세트 분할, 최적 alpha값 및 RMSE값 파악 수행


- 회귀 트리 모델 학습/예측/평가
- XGBoost, LightGBM
- 수행 시간이 오래 걸리므로 최적 파라미터를 적용한 상태에서 수행


- 회귀 모델의 예측 결과를 혼합하여 최종 예측하기
- Ridge 모델 + Lasso 모델


- 스태킹 앙상블 모델을 통한 회귀 예측
- 개별 기반 모델 + 최종 메타 모델(개별 모델의 예측 데이터를 학습데이터로 학습)
- 개별모델, 원래 학습 데이터, 원래 테스트용 데이터를 입력 받음


- 반환된 데이터를 스태킹 형태로 결합부터!

'코딩 > Machine Learning' 카테고리의 다른 글
| 12. 군집화(Clustering) (2) | 2021.01.09 |
|---|---|
| 11. 차원 축소(Dimension Reduction) (1) | 2021.01.03 |
| 9. 회귀(Regression)_2 (0) | 2021.01.01 |
| 8. 회귀(Regression)_1 (0) | 2020.12.27 |
| 7. 분류(Classification)_3 (0) | 2020.12.13 |




댓글