권철민 저, '파이썬 머신러닝 완벽 가이드', 2019.02.28
내 맘대로 요약 공부 중(문제시 비공개 및 삭제)
최초 작성일 2021.1.7
12.1 K-평균 알고리즘
- 군집화(Clustering)의 가장 보편적인 알고리즘 K-평균
- 군집 중심점(centroid)을 임의로 지정하여 각 데이터와의 평균 지점으로 이동하며, 더 이상 중심점의 이동이 없을 경우
반복을 멈추고 해당 중심점에 속하는 데이터들을 군집화

- 두 개의 군집 중심점을 설정하며, 각 데이터는 가까운 중심점에 속함
- 할당된 데이터들의 평균 중심으로 중심점 이동
- 다시, 각 데이터는 가까운 중심점에 속함
- 할당된 데이터들의 평균 중심으로 중심점 이동
- 이동이 없을 때까지 반복
- 거리 기반 알고리즘으로 속성의 개수가 많을수록 군집화 정확도가 낮음
- 반복 수행을 해야 하므로 수행 시간이 느림
- 사전에 몇 개로 군집해야 할지 파악하기 어려움(실험적으로 반복해야 한다는 것을 의미)
- Sklearn KMeans 클래스 활용
- n_clusters = 군집화할 개수, 군집 중심점의 개수 /
- n_init = 초기 군집 중심점의 좌표를 설정할 방식(보통 'k-mean++')
- max_iter = 최대 반복 횟수, 이전에 중심점의 이동이 없을 경우 반복 종료
- fit(데이터 세트), fit_transform(데이터 세트)
- 군집화 완료 후 군집화 속성 확인
- labels_ = 각 데이터 포인트가 속한 군집 중심점 레이블
- cluster_centers = 각 군집 중심점 좌표, Shape는 [군집 개수, 피처 개수], 좌표를 통해 시각화 가능
- 붓꽃 데이터 세트 군집화

- 붓꽃 데이터 세트 3개 그룹으로 군집화
- n_clusters=3, init='k-means++', max_iter=300

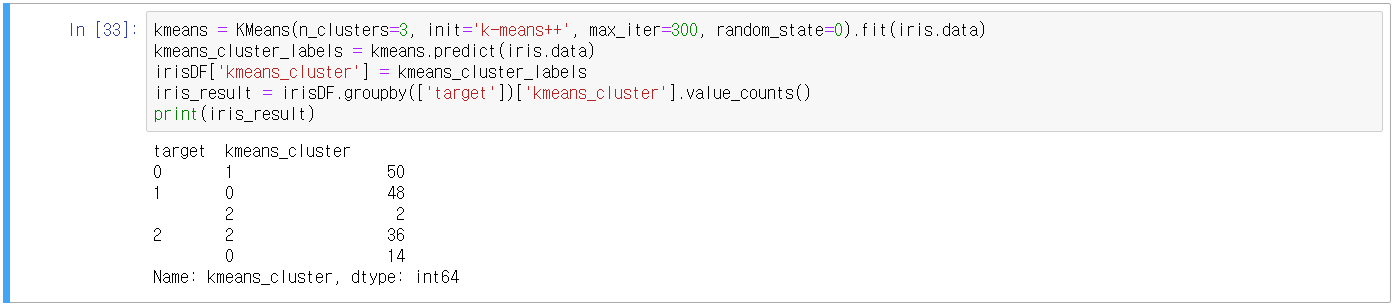
- Cluster Label 값 칼럼 추가


- 분류 target 0은 1번 군집으로 50개
- 분류 target 1은 0번 군집으로 48개, 2번 군집으로 2개
- 분류 target 2는 0번 군집으로 14개, 2번 군집으로 36개
- 분류 target 1, 2는 군집화가 제대로 되지 않았음. 특히 분류 target 2
- 붓꽃 데이터 전체 시각화

- df.loc['row', 'column'] 활용( row에는 행 or 인덱스, column에는 column)

- 군집화 알고리즘 테스트를 위한 데이터 생성기(make_blobs(), make_classification() API)
- make_blobs() → 개별 군집의 중심점과 표준 편차 제어 기능
- make_classification() → 노이즈를 포함한 데이터를 만듦
- make_circle(), make_moon() → 군집화로 해결하기 어려운 데이터 세트를 만듦
- make_blobs() 활용
- n_samples: 생성할 데이터 수, Dafault=100개
- n_features: 데이터의 피처 수, 시각화는 2개로 설정하여 첫 번째 피처는 X 두 번째 피처는 Y로 표현
- centers: int값으로 설정하면 군집의 개수, ndarray로 설정하면 개별 군집 중심점의 좌표
- cluster_std: 생성될 군집 데이터의 표준 편차, list로 표현 시 리스트 순서별로 군집 내의 표준편차를 의미
- np.unique 활용(중복되지 않는 배열을 반환)


- 시각화
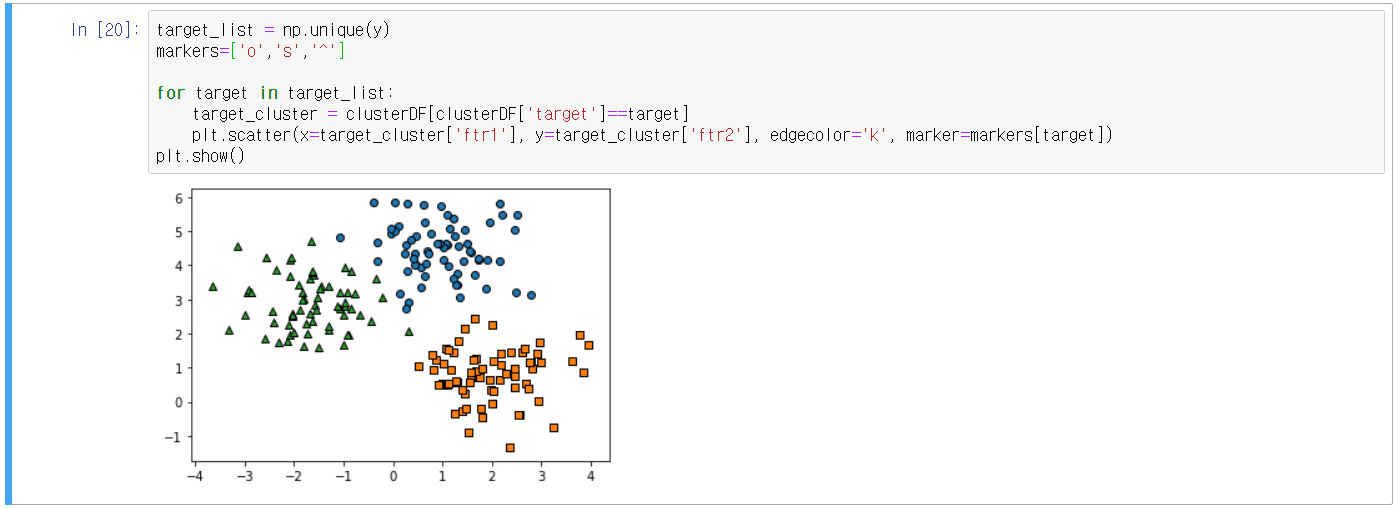
- KMeans 군집화를 수행한 뒤 군집 별로 시각화
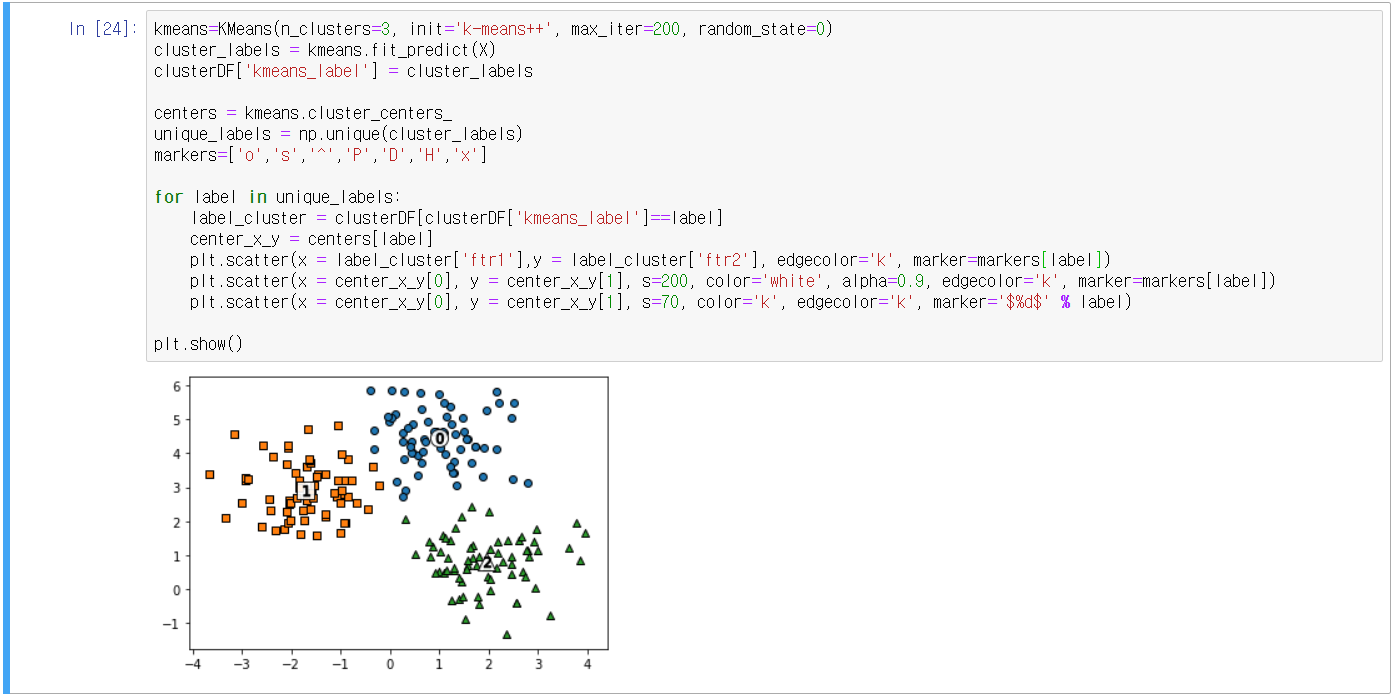
- 매핑 확인

- make_blobs()의 cluster_std 값에 따른 결과 비교

12.2 군집 평가(Cluster Evaluation)
- 군집화는 분류(Classification)와 다르게 데이터 내에 숨어있는 별도의 그룹을 찾아 의미를 부여하는 등 세분화된
군집화를 추구함
- 대표적인 군집 평가 방법: 실루엣 분석(Silhouette analysis)
- 각 군집 간의 거리가 얼마나 효율적으로 분리돼 있는지 나타냄
- 잘 분리될수록 다른 군집과의 거리는 멀고, 동일 군집과의 거리는 가까움
- 개별 데이터가 가지는 군집화 지표인 실루엣 계수(Silhouette Coefficient)를 기반

- 실루엣 계수
- 1에 가까울수록 근처의 군집과 더 멀리 떨어져 있음
- 0에 가까울수록 근처의 군집과 가까움
- 음수(-)는 다른 군집에 데이터가 군집되어 있음을 의미(다시 군집화 해야 함)
- sklean의 실루엣 분석 메서드
- sklearn.metrics.silhouette_samples(X, labels, metric='euclidean', **kwds): X feature 데이터 세트, 각 피처의 레이블 값을 인자로 제공하면 실루엣 계수를 반환
- sklearn.metrics.silhouette_score(X, labels, metric='euclidean', sample_size=None, **kwds): X feature 데이터 세트, 각 피처의 레이블 값을 인자로 제공하면 전체 데이터의 실루엣 계수 값을 평균하여 반환
- 좋은 군집화의 조건
- sklearn의 silhouette_score값이 0~1 사이의 값을 가지며, 1에 가까울수록 좋음
- 전체 실루엣 계수의 평균값과 개별 군집의 평균값의 편차가 크지 않아야 함(여러 개 중 하나만 군집이 잘 될 수도)
- 붓꽃 데이터를 활용한 군집 평가

- 평균 실루엣 계수: 0.553
- 클러스터별 coeff 평균 구하기

- 군집별 평균 실루엣 계수의 시각화 방법
github.com/wikibook/ml-definitive-guide/blob/master/7%EC%9E%A5/7-2_Cluster%20evaluation.ipynb
wikibook/ml-definitive-guide
《파이썬 머신러닝 완벽 가이드》 예제 코드. Contribute to wikibook/ml-definitive-guide development by creating an account on GitHub.
github.com
- 부록 소스코드를 활용
- 4개의 군집 중심의 500개 2차원 데이터 세트를 만들고, k-평균으로 군집화

- 붓꽃 예제로 K-평균 군집화

- 실루엣 계수를 통한 평가방법은 시간이 오래 걸리므로, 군집 별 임의의 데이터를 샘플링하여 실루엣 계수를 평가하는
방법을 고려해야 함
12.3 평균 이동(Mean Shift)
- 특정 대역폭(bandwidth)을 가지고 최초의 확률 밀도 중심에서 데이터의 확률 밀도 중심이 더 높은 곳으로 이동
- 데이터의 분포도를 이용해 군집 중심점을 찾음(확률 밀도 함수)
- KDE(Kernel Density Estimation)
- 대역폭의 크기에 따라 군집화의 품질이 결정
- sklearn의 Meanshift 클래스 활용
- make_blobs() cluster_std=0.8, 3개의 군집 데이터, bandwidth=0.9


- 최적의 bandwidth를 찾기 위해 sklearn의 estimate_bandwidth를 활용

- 군집화 수행

- 시각화 수행


- 평균 이동의 장점
- 평균 이동은 데이터 세트의 형태를 특정 형태로 가정하지 않음
- 평균 이동은 특정 분포도 기반의 모델로 가정하지 않음
- 유연한 군집화 가능
- 평균 이동의 단점
- 수행 시간이 오래 걸림
- bandwidth에 따른 군집화 영향도가 큰 편
- 데이터 세트 조작보다는 이미지 혹은 영상 데이터에서 특정 개체를 구분하거나 움직임을 추적하는 역할을 수행
12.4 GMM(Gaussiaan Mixture Model)
- GMM 군집화: 데이터가 여러 개의 가우시안 분포 모델을 섞어서 생성된 것을 가정하여 군집화 수행
- 가우시안 분포(Gaussian Distribution) = 정규 분포(Normal Distribution) = 평균 0, 표준편차 1

- GMM은 데이터를 여러 개의 가우시안 분포가 섞인 것으로 가정

- 가령, 1000개의 데이터 세트가 있으면 이를 구성하는 여러 개의 정규 분포를 추출하고 개별 데이터가 어떤 정규분포에
속하는지 결정하는 것이 GMM
- GMM의 모수 추정
- 개별 정규 분포의 평균과 분산
- 각 데이터가 어떤 정규 분포에 해당되는지 확률
- GMM은 EX(Expectation and Maximization) 방식으로 모수 추정 군집화
- sklearn의 GaussianMixture 클래스 활용
- 붓꽃 데이터 세트 군집화
- GaussianMixture 객체의 주요 parameter: n_components(gaussian model의 총 개수)

- Target 0은 cluster 0, Target 2는 cluster 1, Target 1은 cluster 2로(90%) cluster1로(10%) Mapping 되었음을 확인
- 비교를 위해 k-평균 군집화를 해 보면
- GMM vs K-평균 비교
- KMeans는 원형의 범위에서 군집화를 수행하므로 데이터가 원형의 범위를 가질수록 군집화 효율이 상승함
- 타원형의 분포를 갖는 데이터를 생성하여 비교 진행
- 부록의 소스코드 활용 visualize_cluster_plot(clusterobj, dataframe, label_name, iscluster=True)
- clusterobj: 사이킷런의 군집 수행 객체, KMeans or GaussianMixture의 fit(), predict()를 완료한 객체, make_blobs()의 경우 None
- dataframe: 피처 데이터 세트와 label 값을 가진 DataFrame
- label_name: 군집화 결과 시각화는 dataframe 내 label 칼럼 명, make_blobs()는 dataframe 내 target 칼럼 명
- iscluster: 사이킷런 Cluster 객체가 군집 중심 좌표를 제공하면 True, 아니면 False

- KMeans 수행

- GMM 수행

- GMM은 K-평균과 다르게 중심 좌표를 구할 수 없음
- Label값 비교

- 문제는 GMM도 수행 시간이 오래 걸림
12.5 DBSCAN(Density Based Spatial Clustering of Applications with Noise)
- 기하학적으로 복잡한 데이터 세트에도 효과적으로 군집화 가능
- 특정 공간 내의 데이터 밀도 차이를 기반으로 함
- 주요 파라미터
- 입실론(epsilon): 개별 데이터를 중심으로 입실론 반경을 가지는 원형의 영역
- 최소 데이터 개수(min points): 개별 데이터의 입실론 주변 영역에 포함되는 다른 데이터의 개수
- 데이터 구분(입실론 영역 내에 포함되는 최소 데이터 개수를 충족하는가 or not)
- 핵심 포인트(Core Point): 주변 영역 내에 최소 데이터 개수 충족하는 해당 데이터
- 이웃 포인트(Neighbor Point): 주변 영역 내에 위치한 타 데이터
- 경계 포인트(Border Point): 주변 영역 내에 최소 데이터 개수 불충족 AND 핵심 포인트를 이웃하는 해당 데이터
- 잡음 포인트(Noise Point): 주변 영역 내에 최소 데이터 개수 불충족 AND 핵심 포인트 이웃하지 않는 해당 데이터
- 입실론 영역 내에 포함되는 최소 데이터 개수 3개로 가정


- sklearn의 DBSCAN 클래스, 주요 파라미터
- eps: 입실론 주변 영역의 반경
- min_samples = 핵심 포인트가 되기 위한 최소 데이터 개수(자신의 데이터 수 포함)
- 붓꽃 데이터 세트 군집화(eps=0.6, min_samples=8)

- Target 유형 3가지(0,1,2), 군집 레이블 2가지(0,1), 노이즈 군집 레이블(-1)
- 시각화(부록의 소스코드 활용, 2차원 평면에서 표현하기 위해 PCA로 2개의 피처로 압축)

- 일반적으로 eps가 클수록 노이즈가 줄고, min_samples가 클수록 노이즈가 많아짐


- DBSCAN 적용(make_circles() 데이터 세트)

- K-평균 군집화

- GMM 군집화

- DBSCAN 군집화

12.6 군집화 예제 실습 - 고객 세그먼테이션(Customer Segmentation)
- 고객 세그먼테이션(Customer Segmentation)은 다양한 기준으로 고객을 분류하는 기법을 지칭
- 지역/결혼 여부/성별/소득/직업/선호 상품군/최근 구매 상품/구매 주기 등의 데이터를 활용
- 고객의 어떤 데이터를 기반으로 군집화 할 것인가?? →RFM 기법
- RECENCY(R): 가장 최근 상품 구입 일에서 오늘까지의 시간
- FREQUENCY(F): 상품 구매 횟수
- MONETARY VALUE(M): 총 구매 금액
- archive.ics.uci.edu/ml/datasets/online+retail 데이터 활용
UCI Machine Learning Repository: Online Retail Data Set
Online Retail Data Set Download: Data Folder, Data Set Description Abstract: This is a transnational data set which contains all the transactions occurring between 01/12/2010 and 09/12/2011 for a UK-based and registered non-store online retail. Data Set Ch
archive.ics.uci.edu
- 데이터 불러오기

- 데이터 결측치 확인(NULL)
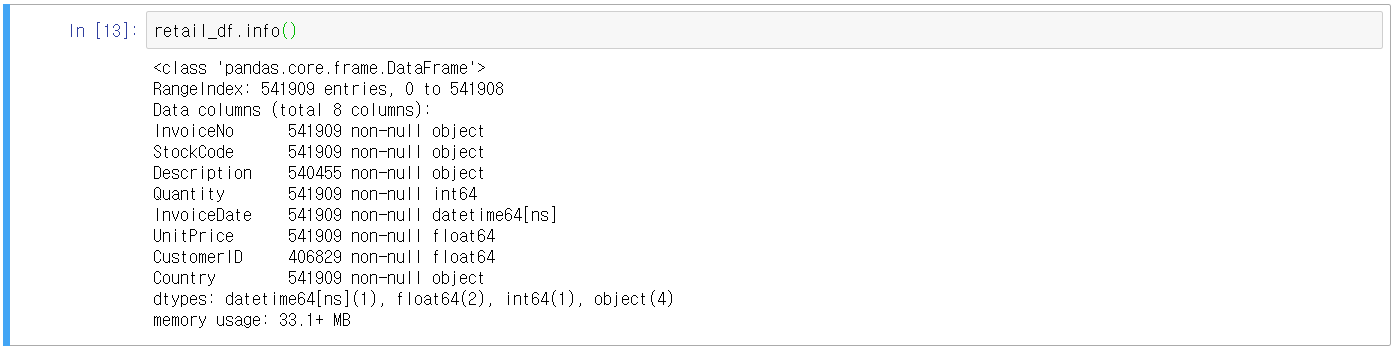
- 데이터 전처리
- NULL 데이터 삭제: CustomerID가 없는 데이터 삭제
- 오류 데이터 삭제: Quantity 혹은 UnitPrice가 0보다 작은 데이터 삭제
- 데이터 정리: 영국을 제외한 국가의 데이터 삭제



- RFM 기반 데이터 군집화 수행
- UnitPrice * Quantity를 곱해서 주문 금액 데이터 생성
- CustomerID int형으로 변경


- 주문번호(InvoiceNo) + 상품코드(StockCode) 기준의 데이터를 고객 기준의 Recency, Frequency, Monetary Valve 데이터로 변경 → RFM 기반의 세그먼트를 수행해야 하기 때문에 데이터를 바꾸는 것임
- 여러 개의 칼럼에 서로 다른 연산법(max, count, sum 등)이 필요하므로 agg() 객체를 활용
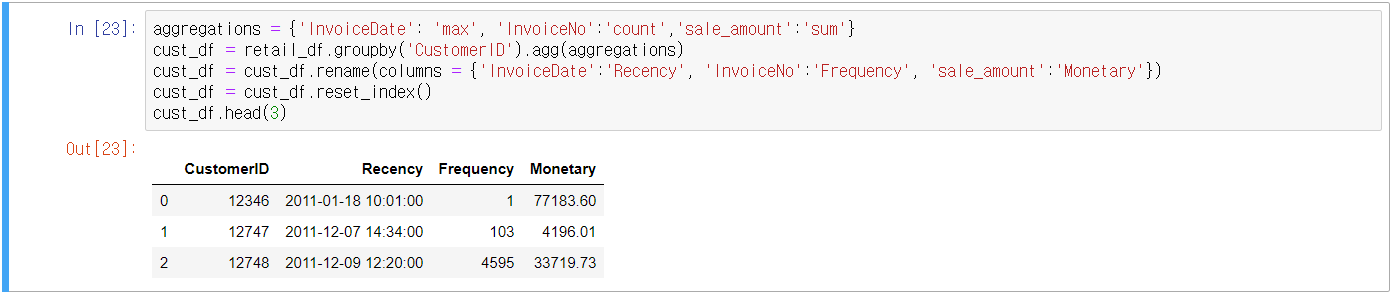
- Recency는 고객이 가장 최근에 주문한 날짜 → 데이터가 2011년 12월 9일까지의 데이터 이므로 2011년 12월 10일을 현재 날짜로 간주하고 가장 최근의 주문 일자를 빼서 데이터 정리 필요

- RFM 기반 고객 세그먼테이션
- 데이터 특성상 판매 데이터에는 소매업체의 대규모 주문이 포함되어 있음 → 왜곡 데이터로 왜곡 군집이 발생함
- 온라인 판매 데이터 세트의 칼럼별 히스토그램을 확인하여 왜곡 데이터 확인

- 각 칼럼의 데이터 값 백분위 확인

- 왜곡을 줄이기 위해 StandardScaler로 평균과 표준편차를 조정하여 K-평균을 수행

- 군집 개수 별 실루엣 계수를 확인
- 부록의 시각화 함수 사용

- 데이터 세트의 왜곡 정도를 낮추기 위해 로그 변환을 시행

- 군집 개수 별 실루엣 계수를 확인

- 결국, 다양한 방법의 데이터 군집화를 수행해가며 최적의 결과를 얻는 노력이 필요
'코딩 > Machine Learning' 카테고리의 다른 글
| 14. 텍스트 분석(Text Analytics)_2 (0) | 2021.01.11 |
|---|---|
| 13. 텍스트 분석(Text Analytics)_1 (0) | 2021.01.10 |
| 11. 차원 축소(Dimension Reduction) (1) | 2021.01.03 |
| 10. 회귀(Regression)_3 (0) | 2021.01.02 |
| 9. 회귀(Regression)_2 (0) | 2021.01.01 |




댓글