권철민 저, '파이썬 머신러닝 완벽 가이드', 2019.02.28
내 맘대로 요약 공부 중(문제시 비공개 및 삭제)
최초 작성일 2021.1.11
14.1 감성 분석(Sentiment Analysis)
- 문서 내 텍스트가 나타내는 여러 가지 단어 및 문맥을 기반으로 감성 수치를 계산하여 분석
- 지도학습은 학습 데이터와 타겟 레이블 값을 기반으로 감성 분석 학습을 수행한 뒤 이를 기반으로 다른 데이 터의 감성 분석을 예측
- 비지도학습은 'Lexicon'으로 불리는 감성 어휘 사전을 이용하여 문서의 긍정적, 부정적 감성 여부를 판단
- 지도학습 기반 감성 분석 실습 - IMDB 영화 리뷰
- 영화 리뷰의 텍스트를 분석해 감성 분석 결과가 긍정 혹은 부정인지 예측하는 모델 생성
- https://www.kaggle.com/c/word2vec-nlp-tutorial/data
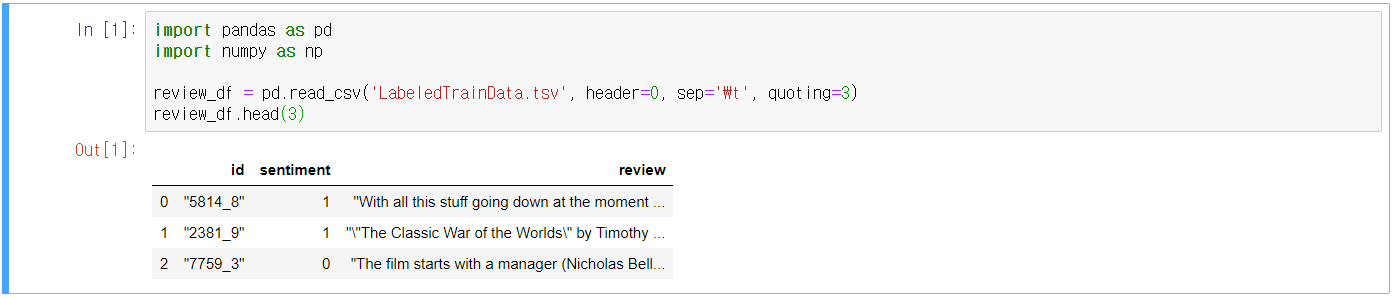

- HTML 태그 = <br /> → 공백으로 변환(replace 활용, 문자열 연산 str 활용)
- 숫자, 특수문자 → 공백으로 변환(정규표현식 활용, 파이썬의 re모듈 활용)

- 결정 값 클래스 sentiment 칼럼을 별도로 추출하여 결정 값 데이터 세트화
- 원본 데이터 세트에서 id, sentiment 삭제하여 피처 데이터 세트화
- train_test_split() 활용하여 데이터 분리(학습용, 테스트용)

- Review 텍스트 피처 벡터화 실행(CountVectorizer, TfidfVectorizer)
- LogisticRegression 적용
- Accuracy 및 ROC-AUC 측정
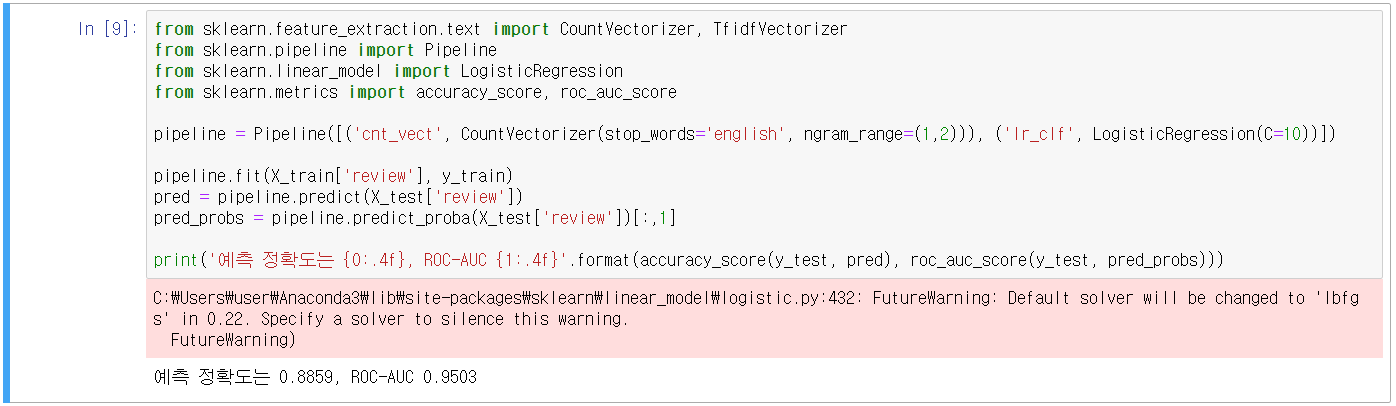

- 비지도학습 기반 감성 분석
- 'Lexicon' : 감성 분석을 위한 감성 어휘 사전(한글용은 없음)
- 감성 지수(Polarity Score)는 단어의 위치, 주변 단어, 문맥, POS(Part of Speech) 등을 참고하여 결정
- NLP 패키지의 WordNet 모듈은 시맨틱(Semantic) 분석을 위한 어휘 사전(Synset 개념: 단어가 갖는 문맥 상의 정보를 제공하는 것)
- 대표적으로 NLTK 패키지의 감성 사전을 사용(예측 성능은 그닥)
- SentiWordNet: WordNet의 Synset 개념을 감성 분석에 적용한 것, 3가지 감성 점수를 할당(긍정, 부정, 객관)
- VADER: 소셜 미디어 텍스트에 대한 감성 분석을 위한 패키지
- Pattern: 최근에 주목받는 패키지, 책에서는 Python 3.x 버전에서는 호환되지 않는다는데 지금도??(찾아보니 3.6 버전 이상에서는 호환되는 듯한다. 점점 늘어나는 듯)
- SentiWordNet을 이용한 감성 분석

- Synset 개념부터 확인

- Synset 객체는 POS(품사), 정의(Definition), 부명제(Lemma) 등으로 시맨틱 요소를 표현할 수 있음

- 서로 다른 어휘 간의 관계를 유사도로 나타낼 수 있음 = synset 객체의 path_similarity() 메서드
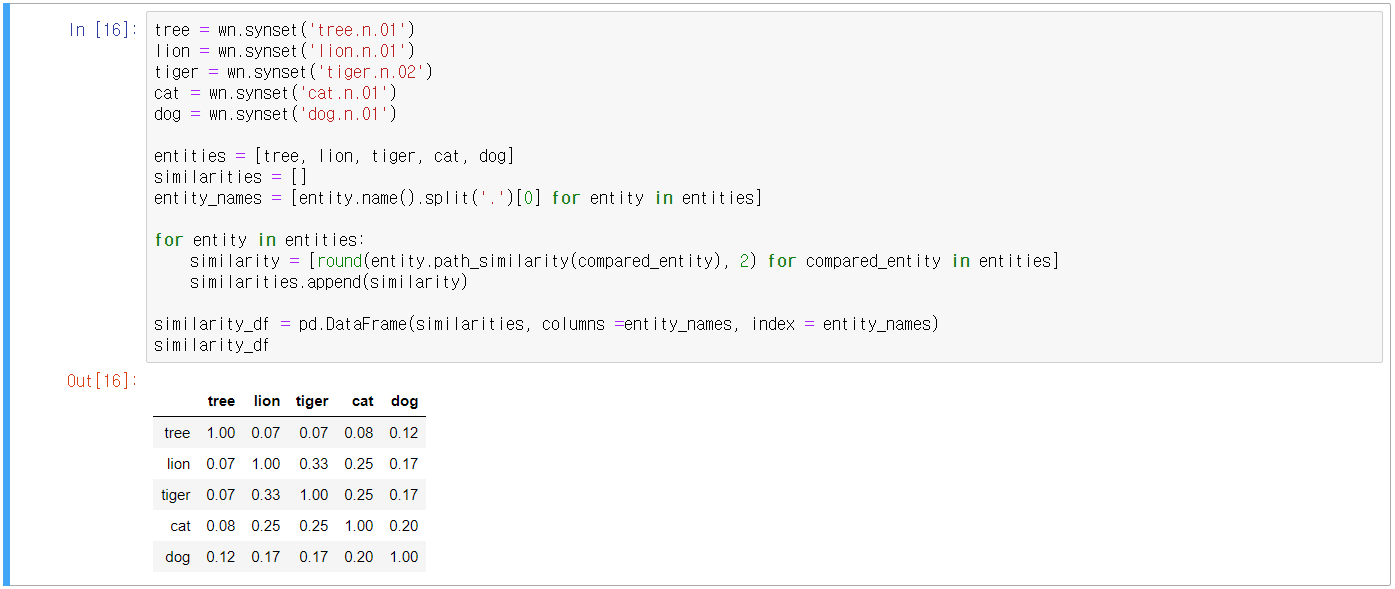
- SentiWordNet의 senti_synset 클래스


- SentiWordNet을 이용한 영화 리뷰 감성 분석
- 문서(Documnet)를 문장(Sentence) 단위로 분해
- 문장을 단어(Word) 단위로 토큰화(어근 추출을 위해 Lemmantization), 품사 태깅
- 품사 태깅된 단어를 기반으로 synset, senti_synset 객체 생성
- senti_synset에서 긍정/부정을 구하고 모두 합산하여 특정 값 이상일 때는 긍정, 이하일 때는 부정으로 결정



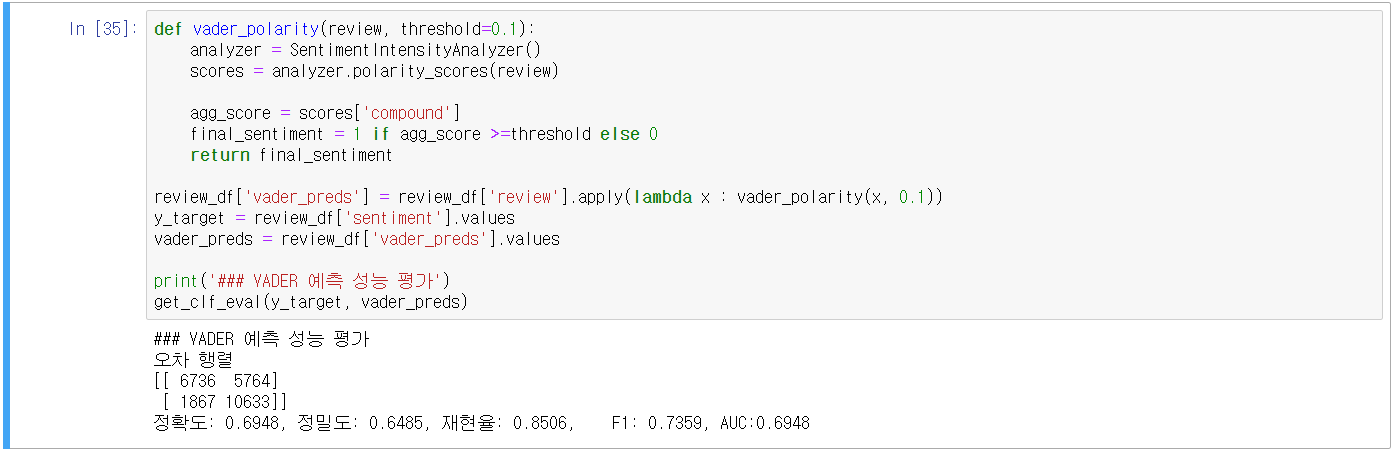
- VADER를 이용한 영화 리뷰 감성 분석
- NLTK VADER의 SentimentIntensityAnnalyzer 클래스를 활용

14.2 토픽 모델링(Topic Modeling) - 20 뉴스그룹
- 토픽 모델링: 문서 집합에 숨어있는 주제를 찾아내는 것, 중심 단어를 함축적으로 추출
- LSA(Latent Semantic Analysis), LDA(Latent Dirichlet Allocation)
- 사이킷런의 LatentDirichletAllocation 활용
- 필요한 주제만 추출하고, 추출된 텍스트를 CountVectorizing(LDA는 CountVec만 사용)
- max_features=1000, ngram_range=(1,2)
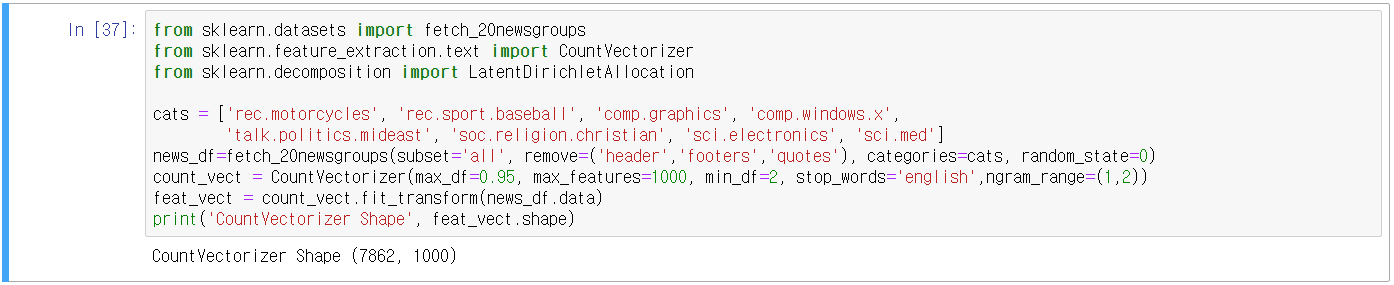
- LatentDirichletAllocation.fit() 수행 후 components_ 속성을 갖게 됨(개별 토픽 별 word피처 수)

- 토픽 별 연관도가 높은 Word를 보기 위해 display 함수 작성

- 성능이 그닥... 좋은지 모르겠음
14.3 문서 군집화와 실습 - Opinion Review 데이터
- 비슷한 텍스트 구성의 문서를 군집화(Clustering) 하는 것
- httparchive.ics.uci.edu/ml/datasets/Opinosis+Opinion+%26frasl%3B+Review
UCI Machine Learning Repository: Opinosis Opinion ⁄ Review Data Set
Opinosis Opinion ⁄ Review Data Set Download: Data Folder, Data Set Description Abstract: This dataset contains sentences extracted from user reviews on a given topic. Example topics are “performance of Toyota Camry†and “sound quality o
archive.ics.uci.edu

- TF-IDF 피처 벡터화
- Lemmatization을 구현한 LemNormalize() 함수 부록 참조
- fit_transfrom()

- 군집화 기법은 K-평균

- 군집화 확인(sort_values(by=정렬칼럼명))




- 3개의 군집으로 군집화 실행
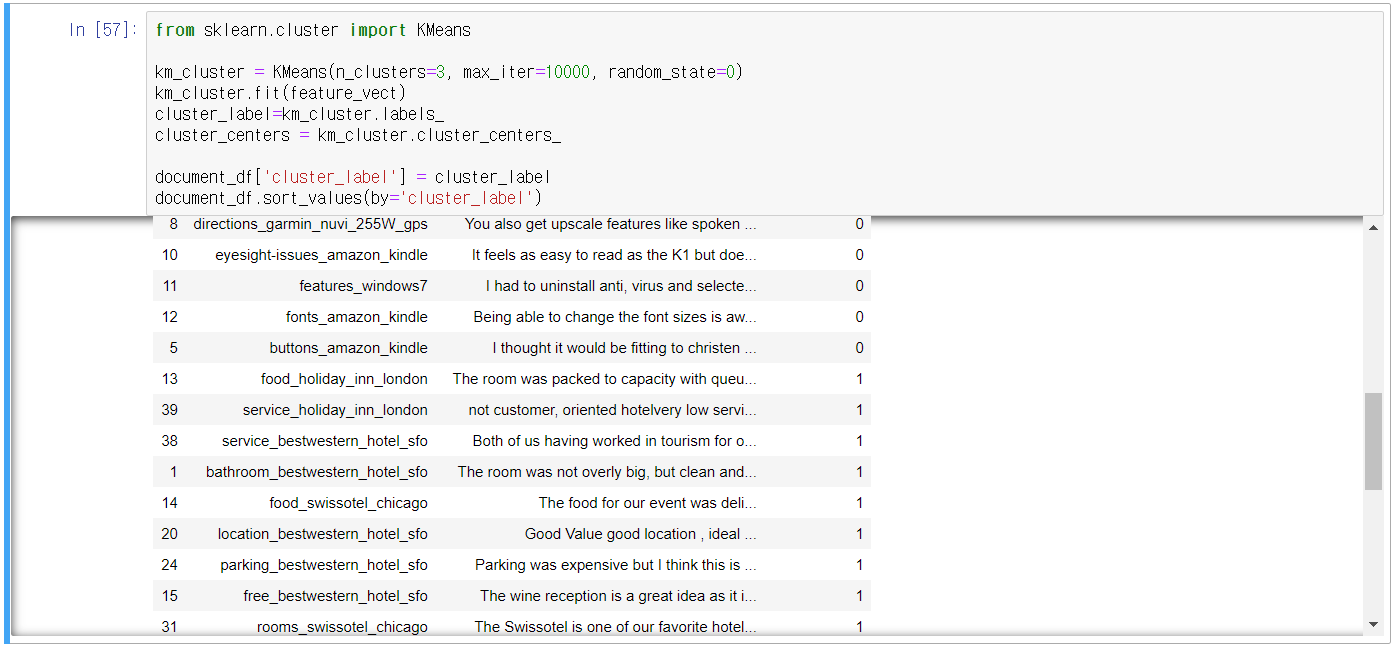
- 군집별 핵심 단어 추출하기
- K-평균은 clusters_centers_ 속성으로 각 군집을 구성하는 단어 피처가 군집의 중심을 기준으로 얼마나 가까운지 알 수 있음
- clusters_centers_는 배열 값으로 행은 개별 군집, 열은 개별 피처를 의미
- clusters_centers_[0,1]은 0번 군집에서 두 번째 피처의 위치 값

- argsort()[:,::-1]을 이용하여 값이 큰 순으로 정렬된 인덱스 값을 반환(인덱스를 알아야 핵심 단어 피처의 이름을 앎)



14.4 문서 유사도
- 코사인 유사도
- 벡터의 크기보다 벡터의 상호 방향성이 얼마나 유사한지에 기반
- 두 벡터의 사잇각을 구해서 얼마나 유사한지 확인
- 두 벡터 사잇각
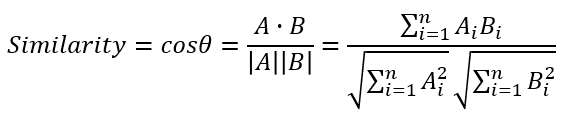
- 간단한 예시



- sklearn의 sklearn.metrics.pairwise.cosine_similarity API 사용
- cosine_similarity() 두 개의 입력 파라미터(첫 번째: 비교 기준 문서 피처 행렬, 두 번째: 비교할 문서 피처 행렬)

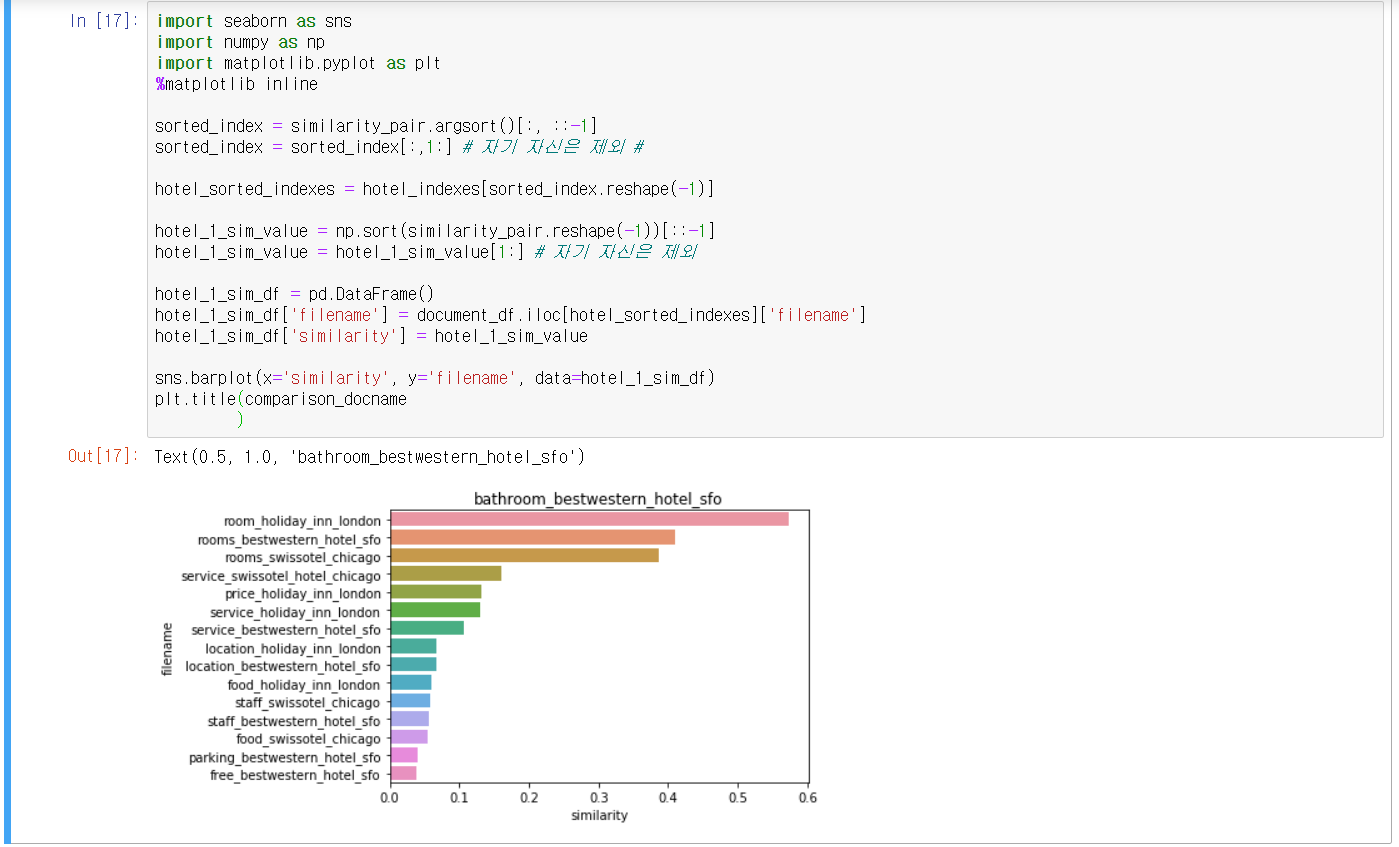
- Opinion Review 데이터 유사도 측정
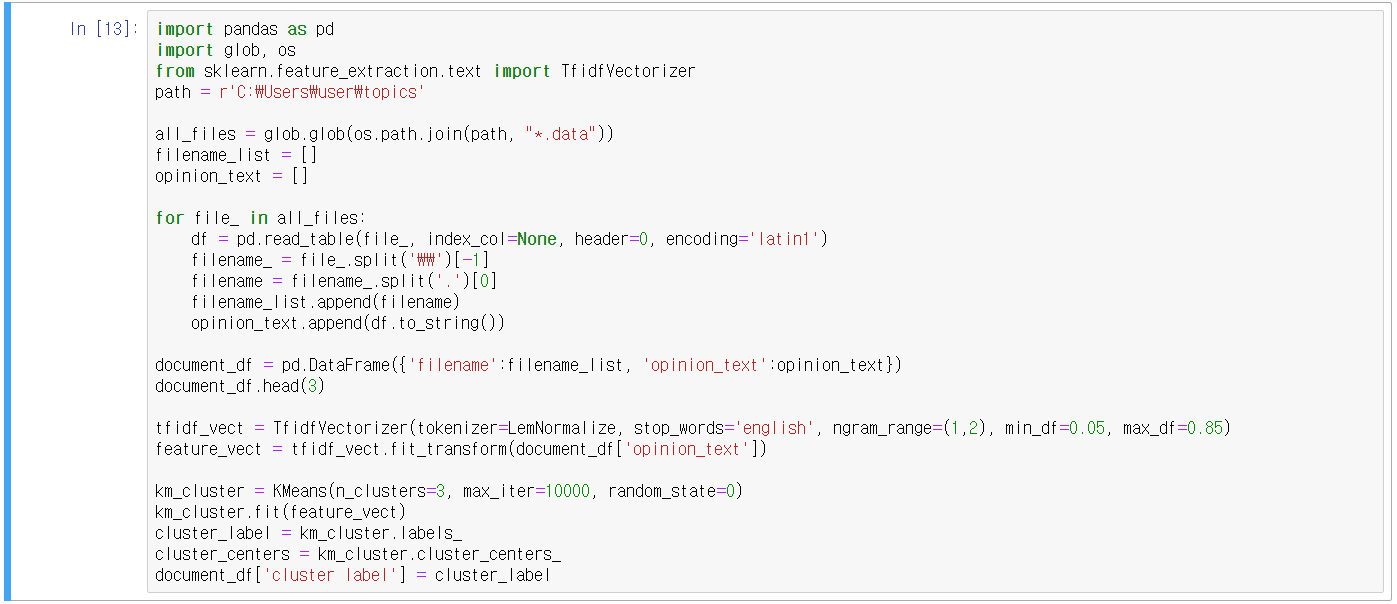

- 유사도를 높은 순으로 정렬하고 시각화
14.5 한글 텍스트 예시 - 네이버 영화 평점 감성 분석
- 한글 언어 처리가 어려운 이유: '띄어쓰기' + '다양한 조사'
- 어근 추출 등의 전처리가 매우 어려움
- 한글 형태소 패키지 KoNLPy
- 다운로드 주소 konlpy-ko.readthedocs.io/ko/v0.4.3/install/#id2
설치하기 — KoNLPy 0.4.3 documentation
주석 설치 및 사용 도중 문제가 발생하는 경우 다음 페이지들을 참고해주세요: 리눅스. 맥 OS. 윈도우. 발생한 문제가 어디에도 없는 경우 “New Issue” 버튼을 눌러 새로운 이슈를 생성해주시기
konlpy-ko.readthedocs.io
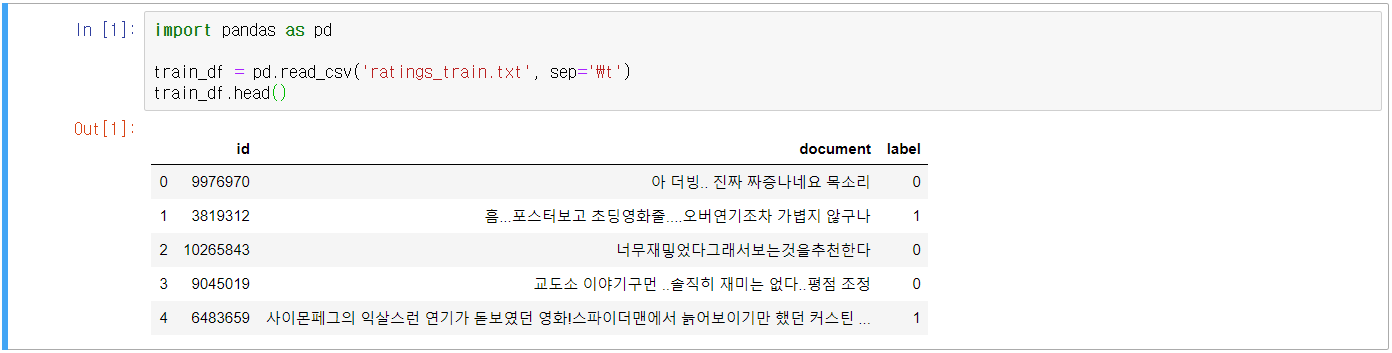
- 네이버 영화 평점 데이터 주소 https://github.com/e9t/nsmc
e9t/nsmc
Naver sentiment movie corpus. Contribute to e9t/nsmc development by creating an account on GitHub.
github.com






14.6 텍스트 분석 실습 - Kaggle Mercari Price Suggestion Challenge
- 일본의 대형 온라인 쇼핑몰인 Mercari사의 제품에 대해 가격을 예측하는 과제
- www.kaggle.com/c/mercari-price-suggestion-challenge/data
Mercari Price Suggestion Challenge
Can you automatically suggest product prices to online sellers?
www.kaggle.com
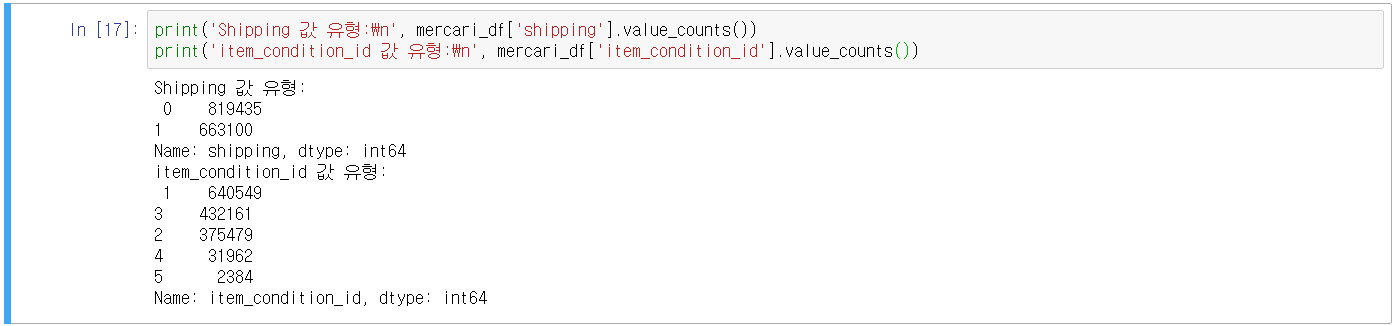
- 데이터 속성 중 price가 예측해야 할 target
- shipping: 배송비 무료 여부(0이면 유료, 1이면 무료)






- category_name 데이터의 '/'를 기준으로 단어를 토큰화해 각각 별도의 피처로 저장하여 학습에 사용
- Men/Tops/T-shirts → 대분류 Men, 중분류 Tops, 소분류 T-shirts
- pandas의 apply lambda로 반환되는 데이터 세트가 리스트 형식임 → DataFrame 칼럼으로 분리해야 함(zip, *)

- 마지막으로, brand_name, category_name, item_description 칼럼의 NULL값 'Other_Null'로 일괄 변경

- 피처 인코딩과 피처 벡터화
- 문자열 칼럼 중 레이블 또는 원-핫 인코딩을 수행할지 피처 벡터화를 수행할지 결정해야 함
- 선형 회귀는 원-핫 인코딩, 인코딩할 피처는 모두 원-핫 인코딩 적용
- 피처 벡터화는 짧은 텍스트는 CountVectorizer, 긴 텍스트는 TF-IDF
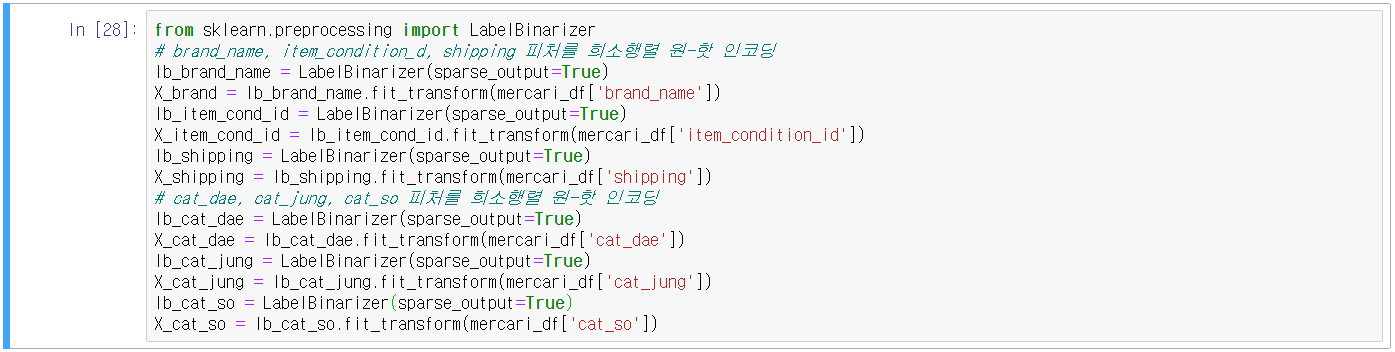
- 1. brand_name는 짧은 문자열로 피처 벡터화 없이, 원-핫 인코딩 적용

- 2. name은 유형이 매우 많고 짧은 문자열이므로 CountVectorizer 피처 벡터화 적용

- 3. category_name은 3개의 칼럼으로 분리되었으며 짧은 문자열로 원-핫 인코딩 적용
- 4. shipping은 1,2 2가지 유형으로 짧은 문자열, 원-핫 인코딩 적용
- 5. item_condition_id는 1,2,3,4,5 5가지 유형으로 짧은 문자열, 원-핫 인코딩 적용
- 6. item_description은 가장 긴 텍스트로, TF-IDF 피처 벡터화 적용

- 주요 칼럼 인코딩 및 피처 벡터화 변환 수행

- 피처 벡터화 반환 데이터는 희소 행렬이므로 인코딩 대상 칼럼도 희소 행렬 형태로 인코딩을 수행
- sklean의 LabelBinarizer 클래스는 희소 행렬 형태의 원-핫 인코딩 지원(sparse_out=True)
- 이후 변환된 모든 희소 행렬들은 Scipy의 sparse 모듈의 hstack() 함수로 결합(희소 행렬을 쉽게 칼럼으로 결합)

- 피처 변환 데이터 세트와 인코딩 데이터 세트를 hstack()을 이용하여 결합
- 많은 메모리를 사용하므로 gc.collect()로 결합 데이터를 메모리에서 삭제하고 할 때마다 다시 결합

- 릿지 회귀 모델 구축 및 평가
- Kaggle에서 제시한 RMSLE(Root Mean Square Logarithmic Error)
- 높은 가격에서 오류가 발생할 경우 오류 값이 더 커지는 것을 최대한 억제하기 위해서 RMSLE를 사용
- RMSLE 수식은 찾아보면 나옴
- 최초 Price를 로그 변환했으므로 원복 시켜 RMSLE를 수행할 수 있도록 함수 생성



- LightGBM 회귀 모델과 앙상블을 활용한 최종 예측 및 평가
- Ridge 모델 예측값 + LightGBM 모델 예측값 앙상블 → 최종 회귀 예측 평가


- 추후 깔끔하게 코드 및 진행과정 정리 필요
'코딩 > Machine Learning' 카테고리의 다른 글
| 16. 단순 선형 회귀 분석(1) (0) | 2021.01.23 |
|---|---|
| 15. 추천 시스템(Recommendations) (0) | 2021.01.13 |
| 13. 텍스트 분석(Text Analytics)_1 (0) | 2021.01.10 |
| 12. 군집화(Clustering) (2) | 2021.01.09 |
| 11. 차원 축소(Dimension Reduction) (0) | 2021.01.03 |




댓글