권철민 저, '파이썬 머신러닝 완벽 가이드', 2019.02.28
내 맘대로 요약 공부 중(문제시 비공개 및 삭제)
최초 작성일 2021.1.13
15.1 추천 시스템의 개요와 배경
- 사용자의 취향을 이해하고 맞춤 상품과 콘텐츠를 제공하는 시스템
- 유튜브, 아마존, 넷플릭스 등 광범위한 범위에서 추천 시스템이 운용되고 있음
- 온라인 스토어의 추천 시스템
- 사용자가 구매한 상품 데이터
- 사용자가 둘러본 상품 및 장비구니에 넣은 상품 데이터
- 사용자의 평점 및 평가 데이터
- 사용자가 작성한 취향 데이터(회원가입 시)
- 사용자의 검색 데이터
- 각종 데이터를 종합하여 사용자에 맞는 콘텐츠를 추천
- 추천 시스템의 유형
- 콘텐츠 기반 필터링(Content Based Filtering)
- 협업 필터링(Collaborative Filtering) → ①최근접 이웃(Nearest Neighbor) 필터링 ②잠재 요인(Latent Factor) 필터링
- 최근 트렌드: ①행렬 분해(Matrix Factorization) 기반 잠재 요인 필터링, ②콘텐츠 & 협업 결합 필터링
15.2 콘텐츠 기반 필터링(Content Based Filtering)
- 사용자가 선택한 콘텐츠와 비슷한 콘텐츠를 추천하는 방식
- 비슷한 것을 추천해주는 방식은 단순함(같은 감독, 같은 장르, 같은 키워드, 비슷한 이름 등등)
15.3 최근접 이웃 필터링(Nearest Neighbor Filtering)
- 사용자가 남긴 평점, 평가, 구매이력 등의 행동 양식(User Behavior)을 기반으로 추천하는 방식
- 즉, 사용자가 평가하지 않은 아이템을 평가한 아이템에 기반하여 예측 및 평가
- 사용자-아이템 행렬에서 행(Row)은 개별 사용자, 열(Column)은 개별 아이템
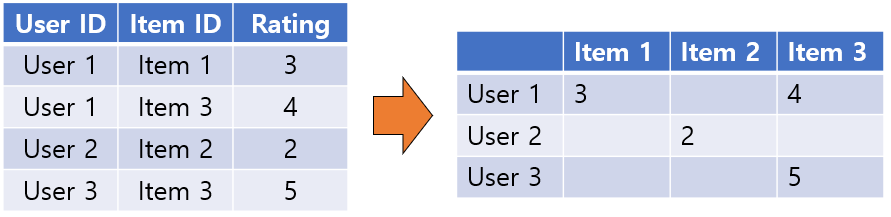
- 일반적으로 사용자-아이템 행렬은 다차원 행렬이며, 희소 행렬(Sparse)의 특징이 있음
- 최근접 이웃 필터링 분류
- 사용자 기반(User-User): 당신과 비슷한 고객들이 다음 상품도 구매했습니다.
- 아이템 기반(Item-Item): 이 상품을 구매한 다른 고객들은 다음 상품도 구매했습니다.
- 둘 다 어디서 많이 본 적이 있다.
- 사용자 기반(User-User)
- 특정 사용자와 타 사용자 간의 유사도(Similarity)를 측정하여 유사도가 높은 타 사용자들이 선호하는 아이템을 추천

- 아이템 기반(Item-Item)
- 사용자들의 아이템 선호도를 바탕으로 추천

- 일반적으로는 아이템 기반 필터링이 정확도가 좋으며, 유사도 측정으로는 코사인 유사도를 적용
15.4 잠재 요인 협업 필터링
- 사용자-아이템 평점 매트릭스 안에 있는 잠재 요인을 추출해 추천 예측하는 방법
- 대규모 다차원 행렬을 SVD 등의 차원 감소 기법으로 분해하면서 잠재 요인을 추출 → 행렬 분해(Matrix Factorization)
- 머신러닝의 블랙박스(Black Box)처럼, 잠재 요인 추출 역시 정확하게 무엇을 추출하는지는 아직 알 수 없음...
- 사용자-아이템 평점 행렬 → ①사용자-잠재요인 행렬, ②잠재요인-아이템 행렬, ③ ①·② 내적 및 예측
- 행렬 분해의 이해
- 다차원 매트릭스를 저차원으로 분해
- 대표적으로 SVD(Singular Vector Decomposition), NMF(Non-Negative Matrix Factorization)

- P는 사용자-잠재요인(M X K) 행렬
- Q는 아이템-잠재요인(N X K) 행렬
- Q.T는 Q의 행과 열을 교환한 전치 행렬
- R행렬은 평점이 없는 NULL값이 많으므로 SVD방법으로 P, Q행렬 분해 불가
- 경사 하강법(Stochastic Gradient Descent) 혹은 ALS(Alternating Least Squares) 방식 활용
- 행렬 분해(확률적 경사 하강법)
- P, Q행렬로 계산된 예측 R 행렬 값이 / 실제 R 행렬과 최소의 오류를 가질 수 있도록 반복적인 비용 함수 최적화로 P, Q를 계산


- pu: P 행렬의 사용자 u행 벡터, qti: Q 행렬의 아이템 i행의 전치 벡터, r(u, i): 실제 R 행렬의 u행 i열에 위치한 값
- r'(u, i): 예측 R' 행렬의 u행 i열에 위치한 값, e(u, i): u행 i열에 위치한 실제 행렬 값과 예측 행렬 값의 차이 오류
- δ: SGD 학습률
- γ: L2 규제(Regularization) 계수
- 파이썬 구현(원본 행렬 R 생성, 분해 행렬 P&Q 정규 분포를 가진 랜덤 값으로 초기화, 잠재 요인 차원 K)

- get_rmse(): 실제 R행렬과 예측 행렬의 오차를 구하는 함수(실제 R 행렬의 NULL이 아닌 행렬 값의 위치 인덱스를 추출해 이 인덱스의 실제 R 행렬 값과 분해된 P, Q를 이용해 다시 조합된 예측 행렬의 RMSE값 반환

- steps: SGD를 반복해서 업데이트할 횟수, learning_rate: SGD의 학습률
- r_lambda: L2 Regularization

- 분해된 P와 Q로 예측 행렬을 만듦

15.5 콘텐츠 기반 필터링 예제 - TMDB 5000 영화 데이터 세트
- www.kaggle.com/tmdb/tmdb-movie-metadata
TMDB 5000 Movie Dataset
Metadata on ~5,000 movies from TMDb
www.kaggle.com
- 장르 속성을 이용한 영화 콘텐츠 기반 필터링
- 다양한 콘텐츠(장르, 감독, 배우, 평점, 키워드, 영화 설명 등)를 기반으로 추천
- 데이터 로딩 및 가공

- genres, keywords 칼럼의 데이터는 리스트 내부에 여러 개의 딕셔너리가 있음(여러 값을 표현하기 위해서)
- ast 모듈의 literal_eval() 함수는 문자열을 list[dict1, dict2] 객체로 만들 수 있음
- genres 칼럼의 'name' 장르명만 추출, keywords 칼럼의 'name' 키워드명만 추출

- 장르 콘텐츠 유사도 측정
- 문자열로 변환된 genres 칼럼을 Count 기반으로 피처 벡터화
- 코사인 유사도로 비교, 데이터 세트의 레코드별로 타 레코드와 장르 코사인 유사도 값을 갖는 객체 생성
- 장르 유사도가 높은 영화 중 평점 높은 순으로 추천


- 유사도 정보를 갖고 있는 genre_sim 행렬을 높은 순으로 정렬하여 인덱스를 가져와야 함
- genre_sim.argsort()[:, ::-1]

- 장르 콘텐츠 필터링을 이용한 영화 추천 함수 생성
- 기반 데이터 movies_df, 유사도 정보를 갖고 있는 genre_sim_sorted_ind, 추천 기준 영화 제목, 추천할 영화 건수


- 왜곡된 평점 데이터를 회피하기 위해 IMDB의 가중 평점(Weighted Rating) 방식 활용

- v: 개별 영화에 평점을 투표한 횟수→vote_count, m: 평점을 부여하기 위한 최소 투표 횟수
- R: 개별 영화의 평균 평점→vote_average, C: 전체 영화 평균 평점



15.6 아이템 기반 최근접 이웃 협업 필터링
- grouplens.org/datasets/movielens/latest/
MovieLens Latest Datasets
These datasets will change over time, and are not appropriate for reporting research results. We will keep the download links stable for automated downloads. We will not archive or make available p…
grouplens.org

- movies.csv 파일은 title, genres / ratings.csv 파일은 userid, movieid, rating, timestamp
- 행 기반 형태의 원본 데이터 세트를 위의 표처럼 행 기반으로 변경해야 함
- pandas의 pivot_table() 활용 / pivot_table(columns='movieid') → movieid 칼럼의 모든 값이 새로운 칼럼으로 변환

- movieId를 title로 바꿔서 알아보기 쉽게, NaN은 0으로 변환

- 영화 간 유사도 산출
- 사용자 간의 유사도가 산출되므로 행렬을 전치하여 코사인 유사도



- 아이템 기반 최근접 이웃 협업 필터링 영화 추천
- 영화 유사도 데이터를 활용하여 개인에 맞는 영화 추천 방식
- 개인화된 예측 평점

- R^(u,i): 사용자u, 아이템 i의 개인화된 예측 평점
- S(i, N): 아이템 i와 가장 유사도가 높은 Top-N개 아이템의 유사도 벡터
- R(u, N): 사용자 u의 아이템 i와 가장 유사도가 높은 Top-N개 아이템에 대한 실제 평점 벡터
- N값은 아이템의 최근접 이웃 범위 계수(Item Neighbor)를 의미
- 위의 item_sim_df와 ratings_matrix 활용, predict_rating() 함수로 R^(u, i) 계산


- MSE로 예측 평가

- 특정 영화와 가장 비슷한 유사도를 가지는 영화에 대해서만 유사도 벡터를 적용하도록 변경
- Top-N 유사도를 가지는 영화 유사도 벡터 예측값 계산 predict_rating_topsim() 함수




- 책 내용이 뒤로 갈수록 조금... 불친절하다.. 코드 또한 다시 정리할 필요가 있다.. 너무 산만하다.
15.7 행렬 분해를 이용한 잠재 요인 협업 필터링
- SGD(Stochastic Gradient Descent) 기반의 행렬 분해
- get_rmse() 함수 그대로 사용
- matirx_factorization(R, K, steps=200, learning_rate=0.01, r_lambda=0.01) 함수
- R: 원본 사용자-아이템 평점 행렬, K: 잠재 요인의 차원 수, steps: SGD 반복 횟수, learning_rate: 학습률, r_lambda=L2 규제 계수


- 데이터 다시 불러오기

- 행렬 분해

- 반환된 예측 사용자-아이템 평점 행렬을 영화 타이틀 칼럼으로 바꿈

- 9번 사용자에 대해서 영화 추천

15.8 파이썬 추천 패키지 - Surprise
- 위에서 배운 알고리즘을 쉽게 구축할 수 있음
- sklearn의 API와 유사함 / fit() / predict() / train_test_split() / cross_validate() / GridSearchCV 등등
다운로드 두 가지 방법
1. pip install scikit-surprise
2. conda install -c conda-forge scikit-surprise
본인은 1번으로 오류가 발생하여 2번으로 설치하였다

- 데이터 로딩은 Dataset 클래스로 가능
- 주요 데이터가 Row(열) 레벨로 되어있는 데이터만 처리 가능
- 무비렌즈(MovieLens) 사이트에서 제공하는 'ml-100k'(100만개 평점 데이터) 데이터를 다운, 로딩 및 분리(Split)

- 데이터를 확인해보면 칼럼 분리 문자가 (\t)임
- Surprise 패키지에서는 이전의 예제처럼 데이터를 변환할 필요 없음(변환 코드 내장되어 있음)
- SVD로 잠재 요인 협업 필터링 시작

- Surprise 패키지에서 추천을 예측하는 메서드 test(), predict()
- test()는 사용자-아이템 평점 데이터 세트 전체에 대해서 추천을 예측

- details 속성은 예측을 할 수 없는 경우를 보여줌(True일 때 예측값을 생성할 수 없다는 의미)
- uid, iid, r_ui, est 등의 속성에 접근하려면 <객체명.uid>와 같은 형태로 가능

- predict()는 개별 사용자와 영화에 대한 추천 평점을 반환(est)

- 테스트 데이터 세트를 이용해 추천 예측 평점과 실제 평점과 차이 평가

- Surprise 주요 모듈 소개
① Dataset
- Surprise는 user_id, item_id, rating 데이터가 로우 레벨로 된 데이터 세트만 적용 가능
- 세 번째 칼럼까지의 데이터만 받아옴, 4개 있으면 3개만 받고 마지막 데이터는 받아오지 않음
- 반드시 데이터 칼럼 순서가 사용자 아이디, 아이템 아이디, 평점 순으로 적용
| API 명 | 내용 |
| Dataset.load_builtin(name='ml-100k' | 무비렌즈 아카이브 FTP 서버에서 데이터를 내려 받음 ml-100k, ml-1M 2개 있음 |
| Dataset.load_from_file(file_path, reader) | OS 파일에서 데이터를 로딩할 때 사용 |
| Dataset.load_from_df(df, reader) | Pandas의 DataFrame에서 데이터를 로딩할 때 사용 |
② OS 파일 데이터를 Surprise 데이터 세트로 로딩
- 로딩되는 데이터 파일에 칼럼명을 가지는 헤더 문자열 같은 게 있으면 제거해야 함

- load_from_file()을 이용해 데이터 로딩
- Reader 클래스의 생성자에 칼럼명, 분리 문자, 최소~최대 평점 입력
- 데이터 로딩 시 앞의 3개 칼럼만 로딩됨(위의 언급이랑 동일)

- line_format: 칼럼을 순서대로 나열, 입력된 문자열을 공백으로 분리해 칼럼으로 인식
- sep: 칼럼을 분리하는 것, Default='\t', Pandas DataFrame의 경우 입력할 필요 없음
- rating_scale: 평점의 최소~최대 평점, Default= (1,5)

③ Pandas DataFrame에서 Surprise 데이터 세트로 로딩
- Dataset.load_from_df() / DataFrame 역시 user_id, item_id, rating 칼럼 순서를 지켜야 함

- Surprise 추천 알고리즘 클래스
| 클래스 명 | 설명 |
| SVD | 행렬 분해를 통한 잠재 요인 협업 필터링 SVD 알고리즘 |
| KNNBasic | 최근접 이웃 협업 필터링 KNN 알고리즘 |
| BaselineOnly | 사용자 Bias, 아이템 Bias를 감안한 SGD 베이스라인 알고리즘 |
- surprise.readthedocs.io/en/stable/prediction_algorithms_package.html 참조
- SVD 클래스 파라미터(n_factors, n_epochs, biased)
- n_factors: 잠재 요인 K의 개수, Default=100, 클수록 과적합 문제 발생
- n_epochs: SGD 수행 시 반복 횟수, Default=20
- Baseline 사용자 편향 적용 여부, Default=True
- Baseline에 대한 설명
- 개인의 성향을 반영해 아이템 평가에 편향성(Bias) 요소를 반영하여 평점을 부여하는 방식
- Baseline 평점 = 전체 평균 평점 + 사용자 편향 점수 + 아이템 편향 점수
- 사용자 편향 점수 = 사용자별 아이템 평점 평균값 - 전체 평균 평점
- 아이템 편향 점수 = 아이템별 평점 평균 값 - 전체 평균 평점
- 교차 검증과 하이퍼 파라미터 튜닝
- Surprise의 cross_validate(), GridSearchCV 클래스
- cross_validate() 인자: 알고리즘 객체, 데이터, 성능평가 방법, 폴드 데이터 세트 개수

- GridSearchCV, 보통 SVD의 경우 n_epochs, n_factors를 튜닝

- Surprise를 이용한 개인화 영화 추천 시스템 구축
- Surprise는 데이터 세트를 train_test_split()을 이용해 데이터를 TrainSet 클래스로 변환하지 않으면 fit()할 수 없음
- 전체 데이터를 학습 데이터로 사용하려면 DatasetAutoFolds 클래스를 사용해야 함

- 학습 데이터를 생성 후, SVD 학습 수행

- userId=9가 아직 평점을 매기지 않은 영화 movidId 42로 선정한 뒤(예제니까 무작위로) 예측 평점을 계산



- 추천 영화는 9696개이며, 이 중 앞에서 학습된 SVD 알고리즘으로 높은 예측 평점을 가진 순으로 영화를 추천함

- 이상으로 권철민 저, '파이썬 머신러닝 완벽 가이드' 요약은 마무리
- 지속적인 공부 및 이해가 필요하다
- 특히 코드 정리 절실하게 필요
'코딩 > Machine Learning' 카테고리의 다른 글
| 17. 단순 선형 회귀 분석(2) (0) | 2021.02.23 |
|---|---|
| 16. 단순 선형 회귀 분석(1) (0) | 2021.01.23 |
| 14. 텍스트 분석(Text Analytics)_2 (0) | 2021.01.11 |
| 13. 텍스트 분석(Text Analytics)_1 (0) | 2021.01.10 |
| 12. 군집화(Clustering) (2) | 2021.01.09 |




댓글