728x90
Luca Massaron, Alberto Boschetti 저, '파이썬으로 풀어보는 회귀분석', 2019.01.02
내 맘대로 요약 공부 중(문제시 비공개 및 삭제)
저작권에 굉장히 민감한 책이므로 일반적인 내용들만 요약
최초 작성일 2021.2.26
1. 모델 생성 및 예측변수와 목표변수 관계 파악
- 여러 개의 예측변수가 있을 경우, 예측변수와 목표변수 사이의 관계 + 예측변수들 사이의 관계를 고려해야 함
- 변수 간의 상호작용 관계를 파악하는 것이 필요

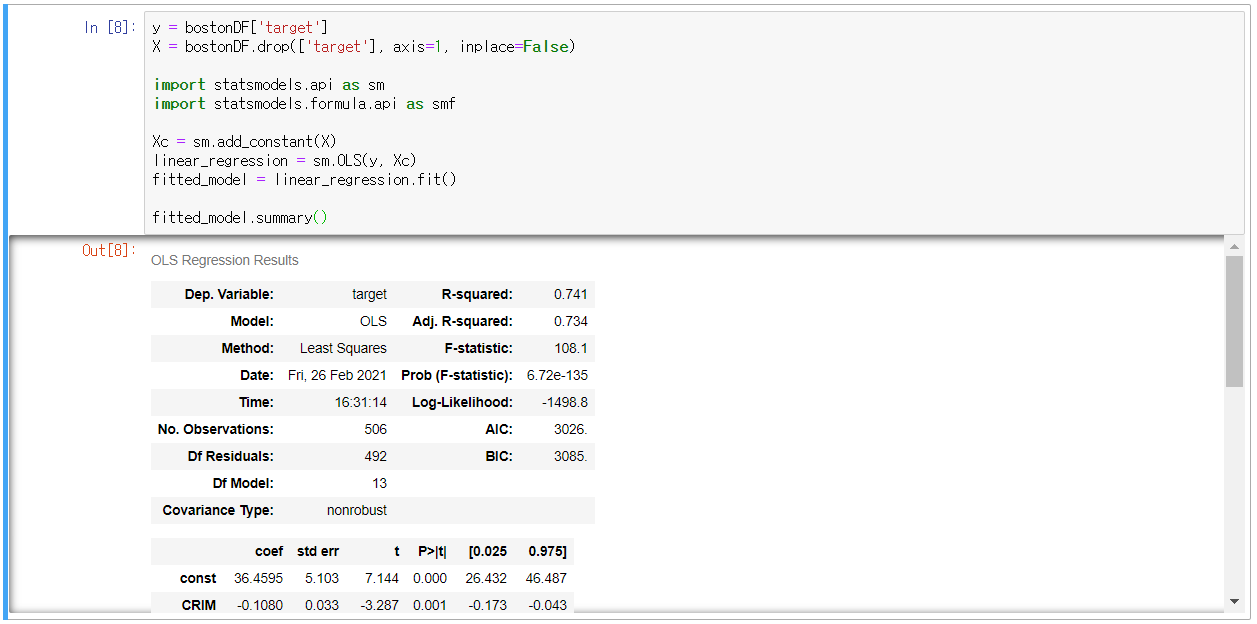
- 다중회귀분석에서는 Adj. R-squared 값과 R-squared 값의 비율이 20%를 초과하지 않아야 함
- 20% 초과한다는 것은 모델에 중복 변수가 있다는 것을 의미(위는 0.741, 0.734로 해당 안됨)

- t값이 낮은(0에 가까운) 변수는 모델에서 제거해도 큰 이상이 없는 변수를 의미
- Cond. No. 값은 30을 초과하면 신뢰도가 매우 낮다는 것을 의미
2. 모델의 예측변수 사이의 관계 파악(히트맵)
- 변수가 많아지기 때문에 선형 회귀에서의 피어슨 상관관계는 큰 역할을 하지 못함
- 응답을 예측하는데 있어서 변수의 독점적인 공헌도 및 직접적인 원인으로서의 영향 정도를 파악
- DataFrame의 corr() 속성을 활용하여 각 예측변수 사이의 상관도를 히트맵 시각화
- annot=True, 각 셀에 숫자를 표시할지 여부
- fmt:'.1g', 0이 아닌 첫번 째 숫자 이하 반올림 'd'는 정수

3. 모델의 예측변수 사이의 관계 파악(고유벡터)
- 고유벡터(eigenvector)는 새로운 변수가 기존 변수와 어떻게 연관되어 있는지 나타내는 행렬
- 고유값(eigenvalue)은 각각의 새로운 변수에 대해 재조합된 분산의 정도를 나타냄 참조
- Numpy의 linarg.eig 활용


반응형
'코딩 > Machine Learning' 카테고리의 다른 글
| 20. 로지스틱 회귀분석(Logistic Regression) (0) | 2021.03.21 |
|---|---|
| 19. 다중회귀분석(2) (0) | 2021.03.03 |
| 17. 단순 선형 회귀 분석(2) (0) | 2021.02.23 |
| 16. 단순 선형 회귀 분석(1) (0) | 2021.01.23 |
| 15. 추천 시스템(Recommendations) (0) | 2021.01.13 |




댓글