728x90
Luca Massaron, Alberto Boschetti 저, '파이썬으로 풀어보는 회귀분석', 2019.01.02
내 맘대로 요약 공부 중(문제시 비공개 및 삭제)
저작권에 굉장히 민감한 책이므로 일반적인 내용들만 요약
최초 작성일 2021.3.2
4. 데이터 스케일링 및 정규화
- 데이터의 일부 특성은 단위 척도에 따라 기본 단위, 소수, 천 단위, Kg 등 다양하기 때문에 데이터 조정 필요
- 동일한 스케일로 조정(단위를 맞춤) OR 동일한 범위로 조정(0~1 사이의 값으로 올 수 있게 정규화)
- StandardScaler 클래스를 이용하여 평균이 0, 분산이 1인 표준 정규화 수행 혹은,
- MinMaxScaler 클래스를 이용하여 최솟값이 0, 최댓값이 1인 정규화 수행 혹은,
- 로그 변환으로 원래 값에 log 함수를 적용하기도 함
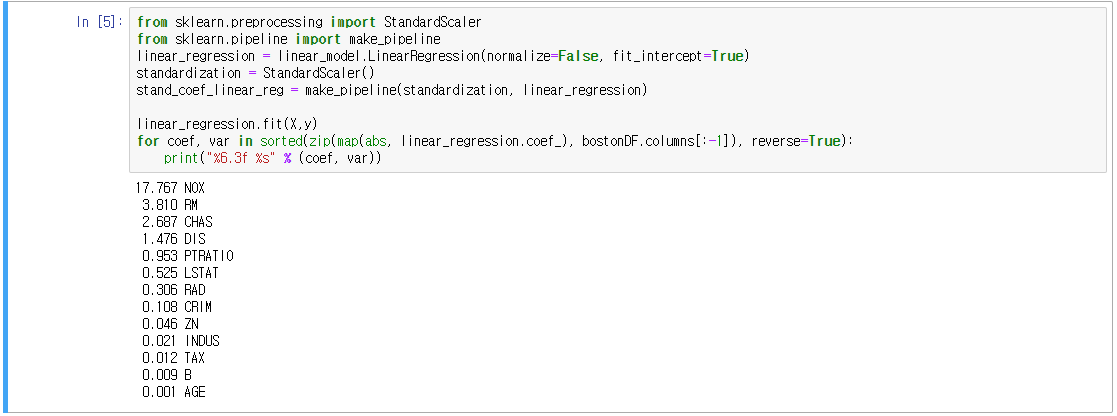

- 다만, 표준화 계수가 크다는 것은 변수가 모델에 중요하다는 것을 의미하지만 단순히 크기만으로 변수끼리의 순위를 매겨서는 안 됨(스케일이 다를 수 있고, 표준편차가 다를 수 있고, 현재 데이터에 상대적이기 때문)
5. 각 피처의 회귀 계수 값 평가
- 첫째, 회귀 계수 값의 방향성(+, -)이 적절한지 평가
- 둘째, 모델에 미치는 변수의 영향력 평가(값이 너무 작다면 제거해야할 필요도 있음, 경제적 필요성)
- 셋째, 값의 크기가 적절한지 평가(너무 크다면 스케일이 다른지, 정규화가 되어있는지 확인 필요)
6. 모델 성능평가 및 시각화




7. 과소 적합 및 과대 적합 분석
- 위에서 볼 수 있듯, 차수가 높을수록 과대적합되어 성능이 감소하게 되는 경우가 있음
- 편향-분산 트레이트오프를 고려하여 적정 차수의, 오류가 최소가 되는 모델을 만들어야 함
8. 시각화까지 간단 코드 정리



반응형
'코딩 > Machine Learning' 카테고리의 다른 글
| 21. 데이터 준비(1) (0) | 2021.03.21 |
|---|---|
| 20. 로지스틱 회귀분석(Logistic Regression) (0) | 2021.03.21 |
| 18. 다중회귀분석(1) (0) | 2021.02.26 |
| 17. 단순 선형 회귀 분석(2) (0) | 2021.02.23 |
| 16. 단순 선형 회귀 분석(1) (0) | 2021.01.23 |




댓글